들어가며
Introduction

어느 회사의 면접장. 면접관은 최종 질문으로 지원자의 장점을 말해보기를 요청하였다. 각종 경제 및 시사 상식, 해당 기업의 창립 년도까지 암기하였으나, 정작 필요한 건 준비하지 않았던 지원자는 엉겁결에 자신은 절약정신이 정말 투철하다며, 회사의 전기(傳記)를 허투루 쓰지 않겠다는 강한 의지를 내비쳤다. 그러나 돌아온 면접관의 ‘그걸 어떻게 알죠?’라는 물음에 면접장의 분위기는 급격히 얼어붙었다. 다른 것은 고만고만했으나 EQ(감성 지수)만은 확실히 뛰어났던 지원자는 면접관들의 비언어적 표현을 통해 자신의 면접이 망했음을 직감하였다. 그렇게 마지막 인사를 하고 터덜터덜 면접장을 나오며, 지원자는 습관적으로 불을 끄고 방을 나왔다. 그는 그 회사에 최종 합격하였다.
이 사례가 우리에게 주는 교훈은 자명하다. ‘회사의 전기(傳記)를 허투루 쓰지 말자.’ 강남역에서 술을 마시다보면, 주변 사무실에 새벽까지 층 전체에 불이 들어와있는 것을 목격하곤 한다. 그 층에 사람이 몇 명이나 있을지는 모르겠으나, 기껏해야 한 두명이라면 해당 기업의 CEO는 매우 분노할 것이다. 따라서 우리는 주어진 공간에 실제로 사람이 있는지 판별해주는 모델을 설계하여, 필요한 곳에만 조명이 들어오게 함으로써 회사의 영업이익 극대화에 기여하고 CEO로부터 칭찬을 듣고 싶었다.
데이터 요약
- 사용된 데이터 : Occupancy Detection Data Set
- 데이터 출처 : UCI Machine Learning Repository(https://archive.ics.uci.edu/ml/datasets/Occupancy+Detection+)
- 시간 단위로 측정된 사람의 재실 여부와 그에 관련 있을 것으로 보이는 5가지 변수 + 날짜 및 시간
- 측정 기간
- training data : 15.02.04(수) 17시 51분 ~ 15.02.10(화) 09시 33분
- test data : 15.02.02(월) 14시 19분 ~ 15.02.04(수) 10시 43분
- test data2 : 15.02.11(수) 14시 48분 ~ 15.02.18(수) 09시 19분
변수 이름 및 설명
- datetime : 년, 월, 일, 시, 분. 초
- Temperature : 섭씨로 측정된 사무실의 온도
- Humidity : 사무실의 습도(%)
- Light : Lux 단위로 측정된 사무실의 빛의 밝기
- CO2 : ppm 단위로 측정된 사무실의 이산화탄소 농도
- Humidity Ratio : 온도와 습도를 이용하여 kgwater-vapor/kg-air 방식으로 계산된 습도 비율
- Occupancy : 1이면 재실중, 0이면 사람이 없는 상태. 반응 변수로 사용.
주제 선정의 배경
처음 데이터를 접하고 주제를 선정하기 전에 간단한 EDA를 동해 데이터를 탐색하던 중, 한 가지 특이한 사실을 발견하였다. 아래 그림을 확인해보자.
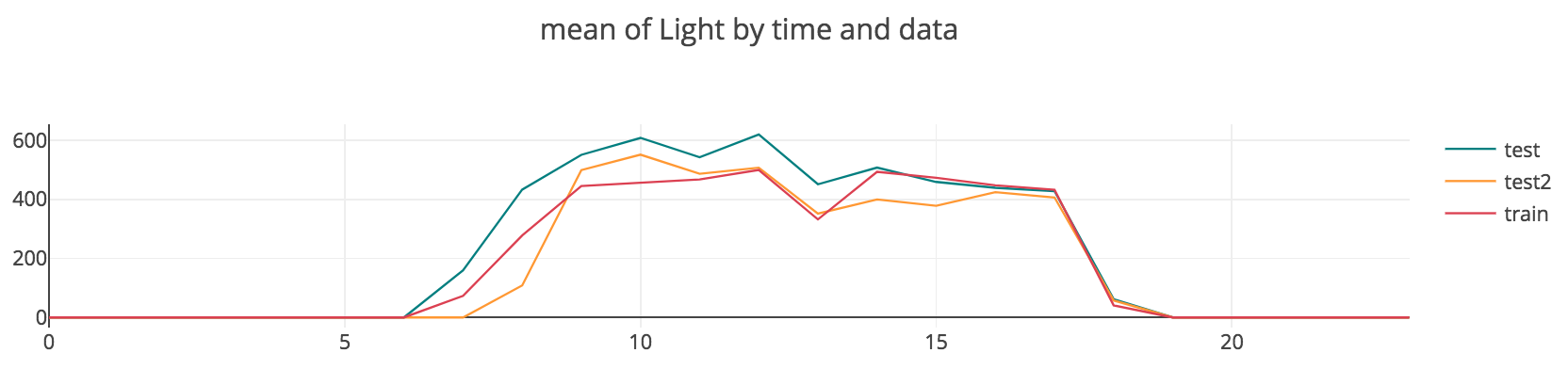
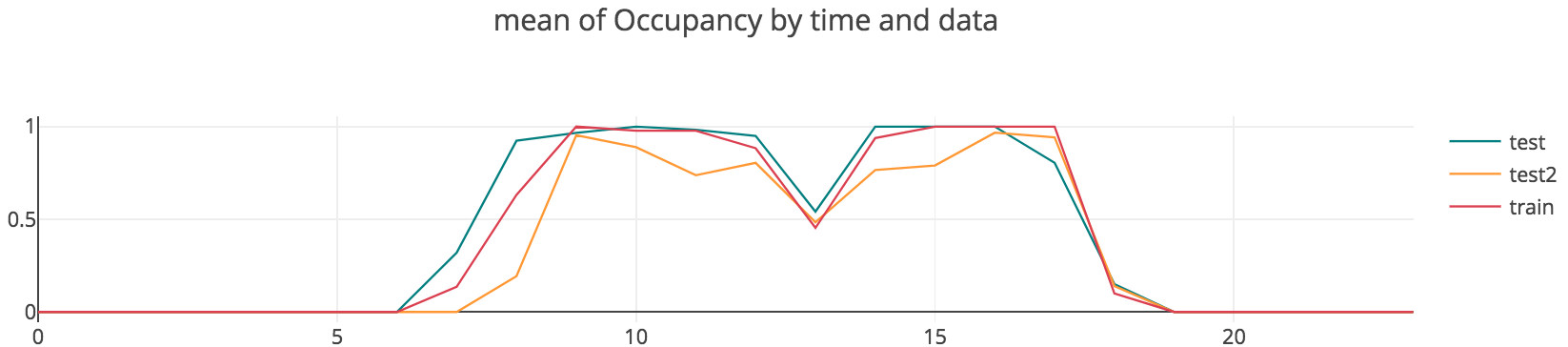
위의 그림은 training과 test 데이터에 대하여, 평일의 시간대별 빛의 밝기의 평균값을 그린 것이다. 아래는 같은 조건 하에서 시간대별 평균 재실 비율을 그린 것이다. 두 그래프가 놀랍도록 비슷하게 생긴 것을 확인할 수 있다. 그 이유를 상식적으로 추정해보았을 때, 사무실에 사람이 있는데 굳이 불을 끄고 있을 이유가 없고, 퇴근할 때 불을 켜둘 이유가 없기 때문이라고 생각하였다. 만약 그런 일이 일어난다면, 사무실 사람들이 실수를 했든, 연구자를 일부러 방해하려고 했든 둘 중의 하나일 것이다. 따라서 먼저 간단히 light 변수만으로 재실 여부를 추정해보기로 하였다. Binary classification 문제에 사용되는 가장 간단한 모델인 로지스틱 회귀를 수행해보았으며, 그 결과는 아래와 같다.
- training accuracy : 98.25%
- test1 accuracy : 97.86%
- test2 accuracy : 99.17%
위에서 확인할 수 있듯이, 결과가 매우 잘 나온다. Test set에 대하여 99.17%의 분류 정확도를 보인다는 것은, 일반화도 매우 잘된 모델이라는 의미이다. 사실 단순히 사람이 재실 중이다 혹은 아니다를 분류하고자 한다면, 이 정도에서 끝내도 충분히 괜찮은 연구지만 이 연구에는 큰 문제가 하나 있다. 도대체 이 분류의 목적은 무엇인가? 로지스틱 회귀 분석이 이렇게나 강력한 모델이다를 자랑하고 싶은게 아니라면 그닥 쓸모는 없어보인다. 따라서 우리는 사람이 없으면 불을 끌 수 있도록 모델을 통해 파악해보자 라는 실용적인 목표를 설정하였다. 이를 위해서, 분석 과정에서 Light 변수는 독립변수로 사용하지 않았다.
EDA
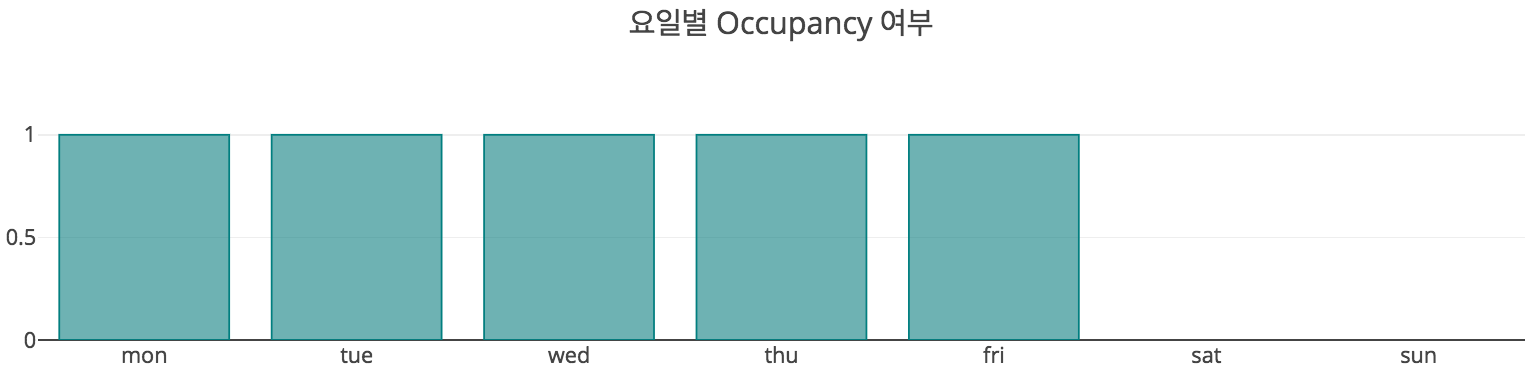
주말 출근 여부
분류 문제를 수행하기 위해여 먼저 데이터를 탐색적으로 분석해보았다. 가장 먼저 궁금했던 것은, 이 회사가 요일에 따라 재실 여부가 다른지 파악하는 것이었다. 외국계 회사일테니, 주말에는 출근을 안 할 것으로 예상되었지만, 혹시라도 52시간 근무제를 지키지 않는 악덕 기업일 가능성도 있으니, 한 번 살펴보고자 하였다. 다행히도 주말에는 출근하지 않는 기업이었다. 근로기준법 준수는 매우 중요하다.
데이터 간의 동질성 파악
다음으로 궁금했던 것은, training 데이터와 test 데이터들 간의 동질성 여부였다. 이 데이터는 같은 장소에서 서로 다른 날짜에 측정된 것이기 때문에, 여러 외부적인 요인들로 인해 두 데이터가 서로 다른 형태를 띌 가능성이 있다고 보았다. 따라서 각 데이터셋에 대하여 변수의 시간대별 평균값을 구해서 비교해보기로 하였다. 이때, 위에서 확인할 수 있듯이 주말에는 출근을 하지 않았기 때문에, 주말을 포함하고 있는 training 데이터와 test2 데이터에서는 주말의 경우를 제외하고 평균값을 취해주었다.
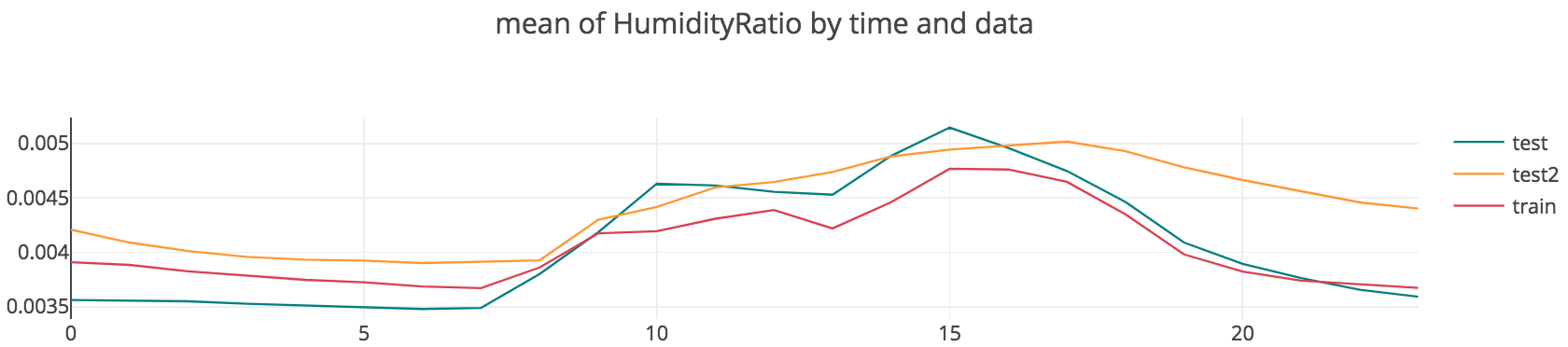
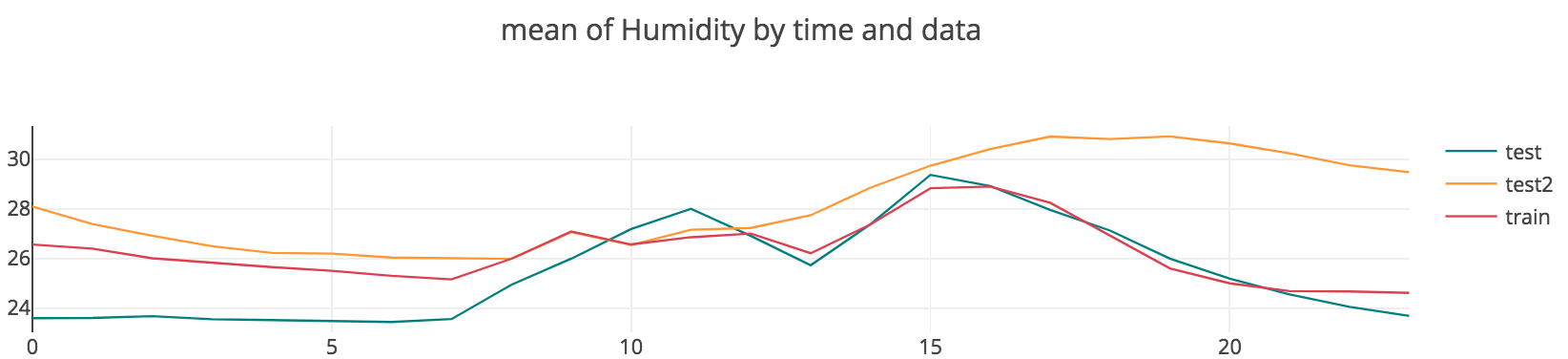
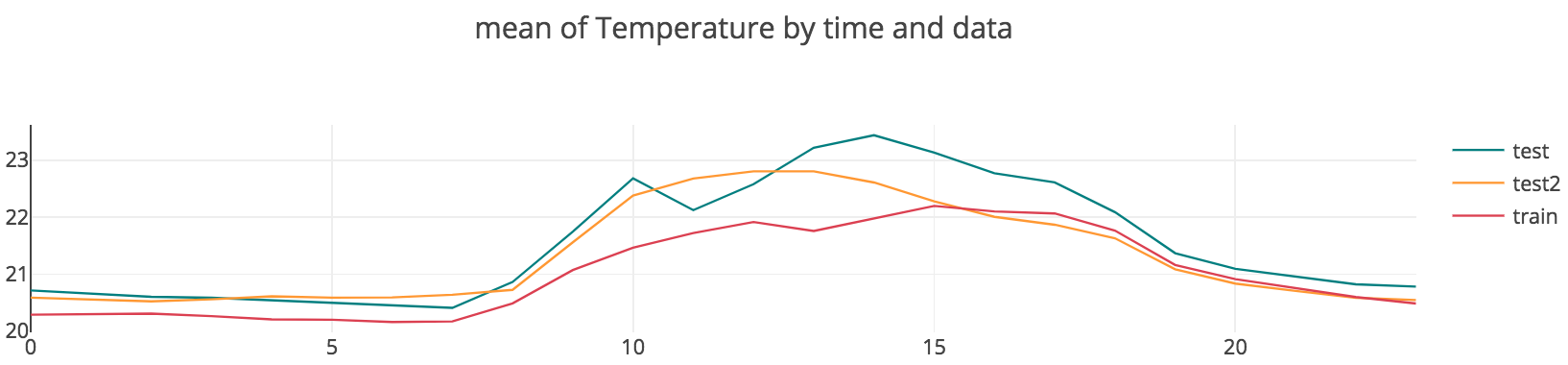
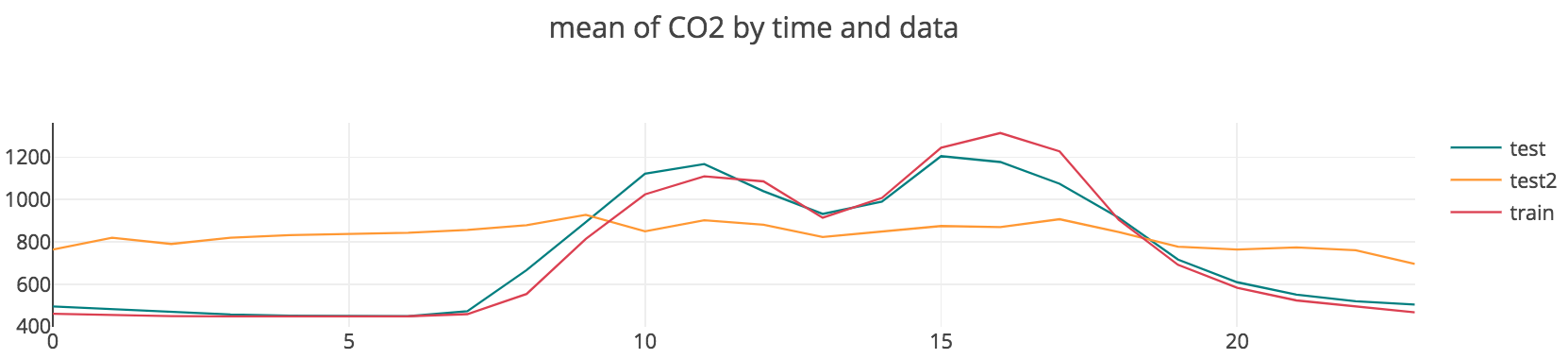
대부분의 경우 training 데이터와 test1, test2 데이터의 형태가 비슷했으나, test2 데이터의 경우, CO2와 Humidity가 나머지 두 데이터와 약간 다른 형태를 띄는 모습이 보였다. 하지만 이 경우에도 전체적인 trend는 비슷하다고 보였기 때문에, training data를 이용하여 학습된 모델을 test 데이터들의 occupancy 추정에 사용하는 것이 타당하다고 판단하였다.
Occupancy와 독립변수 간의 관계 파악
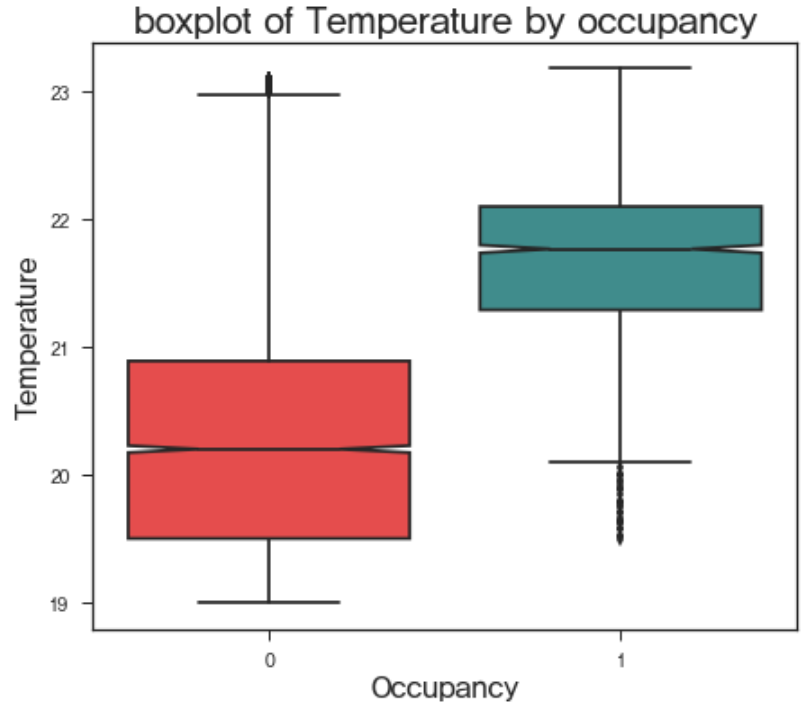
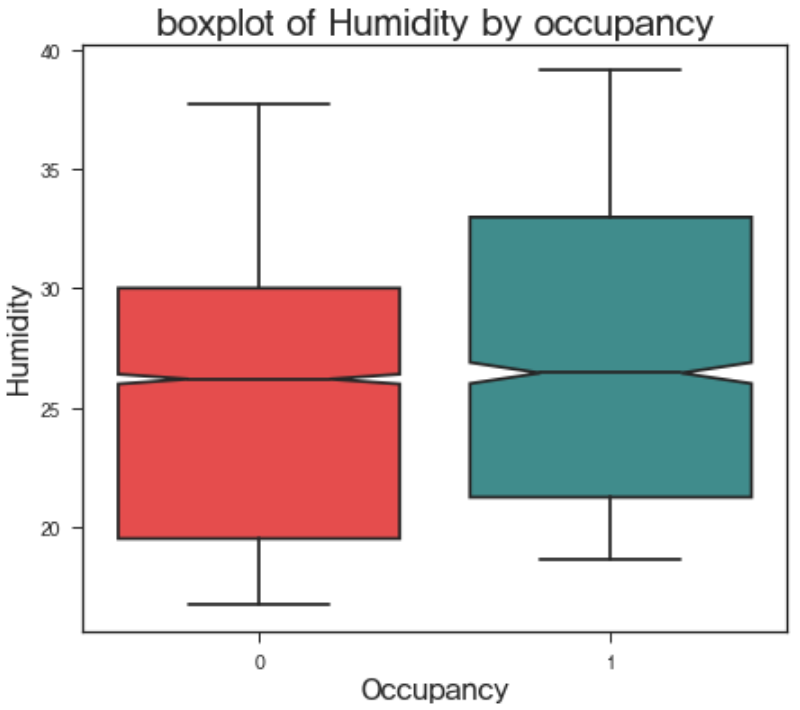
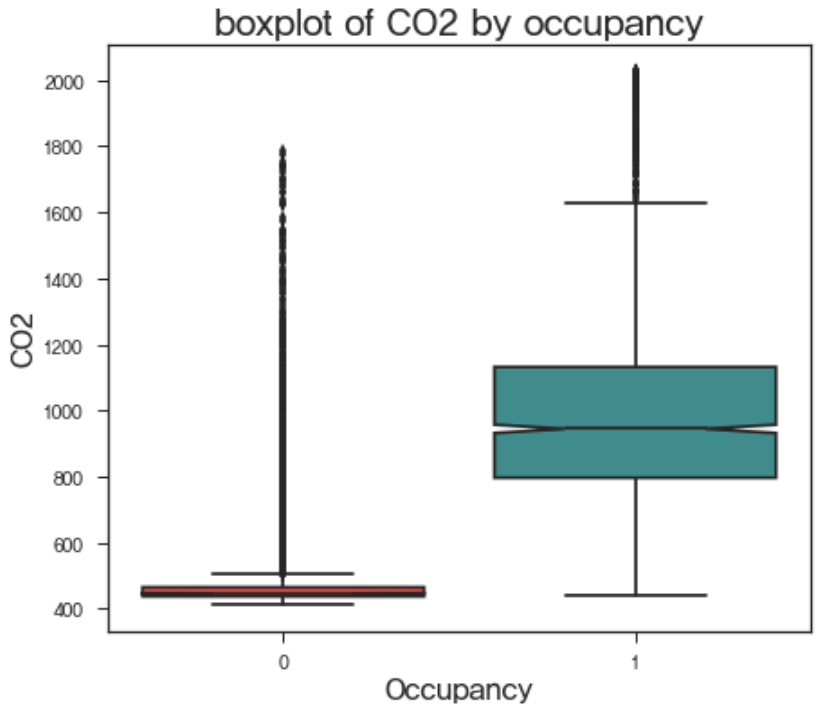
현재 주어진 연속형 독립 변수는 Temperature, Humidity, CO2, Humidity Ratio 이며 이를 이용하여 Occupancy, 즉 재실 여부를 파악하기 위해서는 해당 변수들이 재실 여부에 대하여 서로 다른 값을 가져야할 것이다. 예를 들어, x라는 변수로 y가 1 또는 0인지를 예측하고자 할 때, y값에 무관하게 x가 비슷한 형태를 가지고 있다면, 이는 y를 분류하는 데에 사용하기 힘들 것이다. 이 판단을 돕는 다양한 방법들이 있지만, 여기서는 boxplot을 이용하여 살펴보았다.
| . | . |
|---|---|
 |
 |
 |
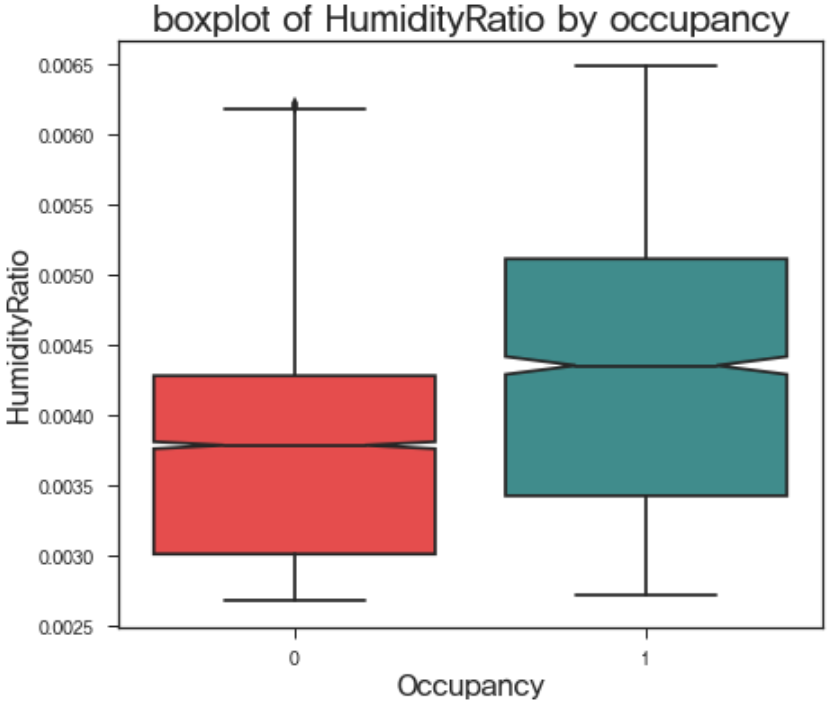 |
위의 boxplot을 이용하여, 우리는 occupancy에 따른 각 변수의 대략적인 분포를 파악할 수 있다. 각각의 box에서 색칠된 구간은 해당 변수의 50%가 존재하는 구간이며, 가운데에 쪼개지는 부분은 변수의 중위값이 존재하는 곳이다. 중위값을 기준으로 위아래가 조금씩 파여있는 것을 확인할 수 있는데, 이 부분을 notch라고 한다. 만약 서로 다른 그룹간에 notch가 겹치지 않는다면, empirical하게 95% 신뢰수준 하에서 두 그룹의 변수값의 분포는 서로 유의미하게 다르다는 판단을 내릴 수 있다. 위의 boxplot으로 대략적으로 판단해볼 때, temperature, co2, humidity ratio는 재실 여부에 따라 그 분포가 유의미하게 다를 것으로 보인다. 하지만 humidity의 경우, 재실 여부에 따른 분포 차이가 유의미하지 않아 보인다. 물론 이는 empirical한 결론이기에 확정적으로 말할 수는 없으나, 현재로써는 humidity를 독립변수에서 제거하고, humidity ratio와 나머지 변수를 사용하는 것이 옳다고 보여진다.
독립 변수 중에서 연속형이 아닌 변수는 datetime이다. 우리는 이 변수를 요일, 시간대로 나누어서 분석에 사용하고자 하였다. 이렇게 변수를 나누기 위해서는 위의 boxplot과 마찬가지로, 각 경우에 재실 비율이 다른 형태를 띄어야할 것이다.
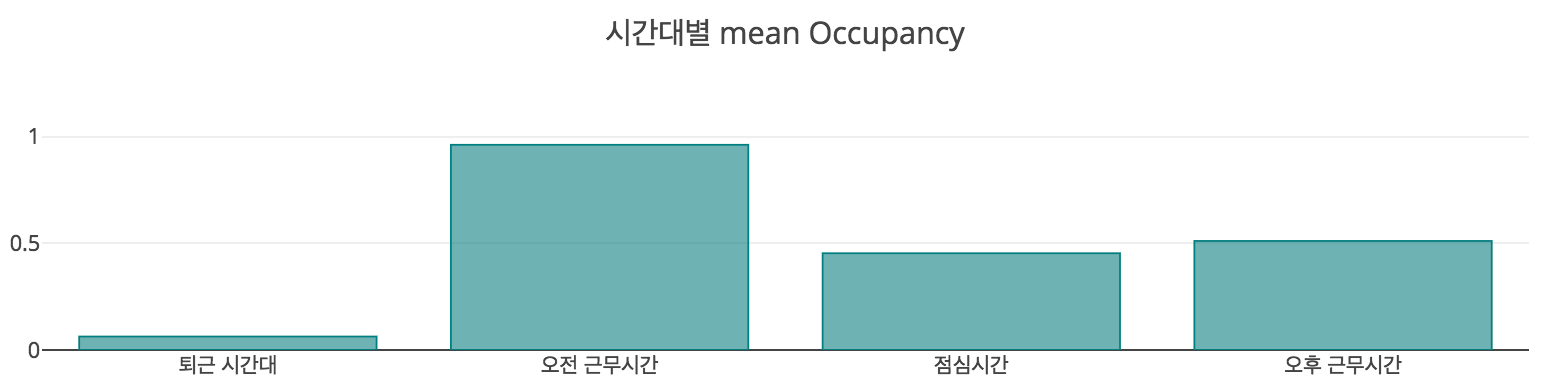
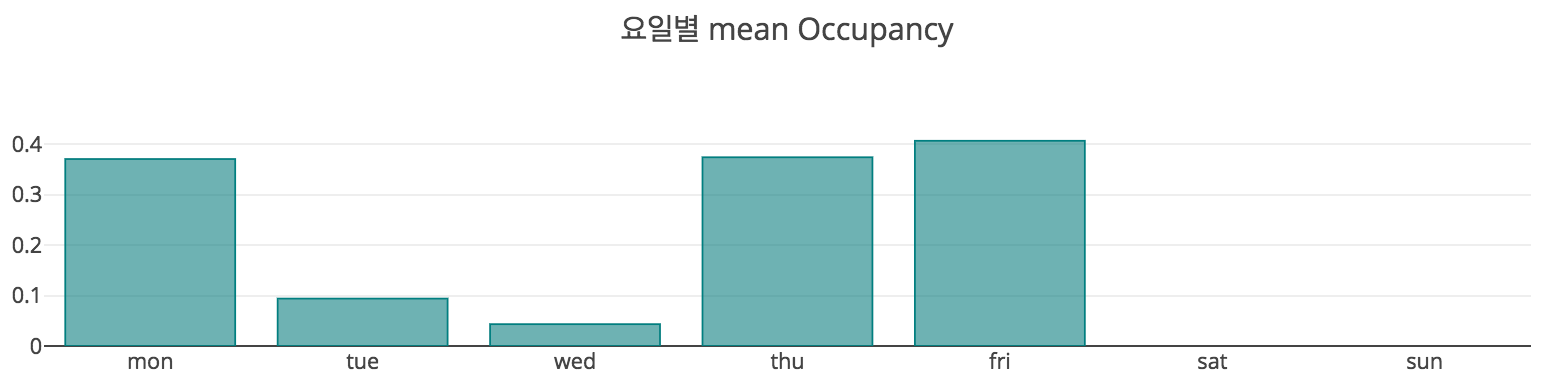
위의 plot을 통해 각 요일별, 시간대별 재실 비율을 확인할 수 있다. 먼저 시간대별 재실 비율을 확인해보자. 시간대는 재실 비율을 연속형으로 그린 뒤, 그 형태가 가장 크게 구분되는 네 개의 구간으로 쪼갰다.
- 09~13시 : 오전 근무
- 13~14시 : 점심 시간
- 14~21시 : 오후 근무
- 21~09시 : 퇴근 시간
당연히 예상할 수 있듯이, 퇴근 시간대에는 재실 비율이 매우 낮았다. 이 회사는 야근이 거의 없는 행복한 회사임이 분명하다. 그 다음으로는 점심시간 재실 비율이 낮았다. 오후보다는 오전에 재실 비율이 낮았으며, 특히 오전에는 재실 비율이 거의 1에 근사했다. 이로 미루어 짐작할 때, 이 회사는 지각을 허용하지 않는 빡빡한 회사인 것으로 보인다. 오후 시간대에는 반차나 조기 퇴근 등의 다양한 이유로 재실 비율이 오전보다는 낮은 것이라고 생각하였다. 이처럼 재실 비율이 시간대별로 다르다는 것은, 시간대를 재실 여부 파악에 사용하여도 된다는 의미로 보인다.
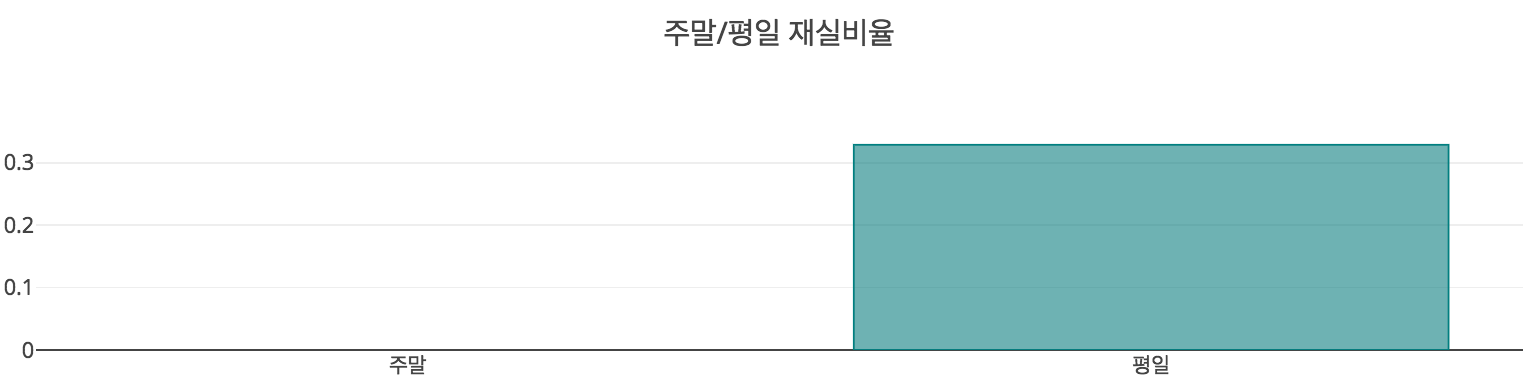
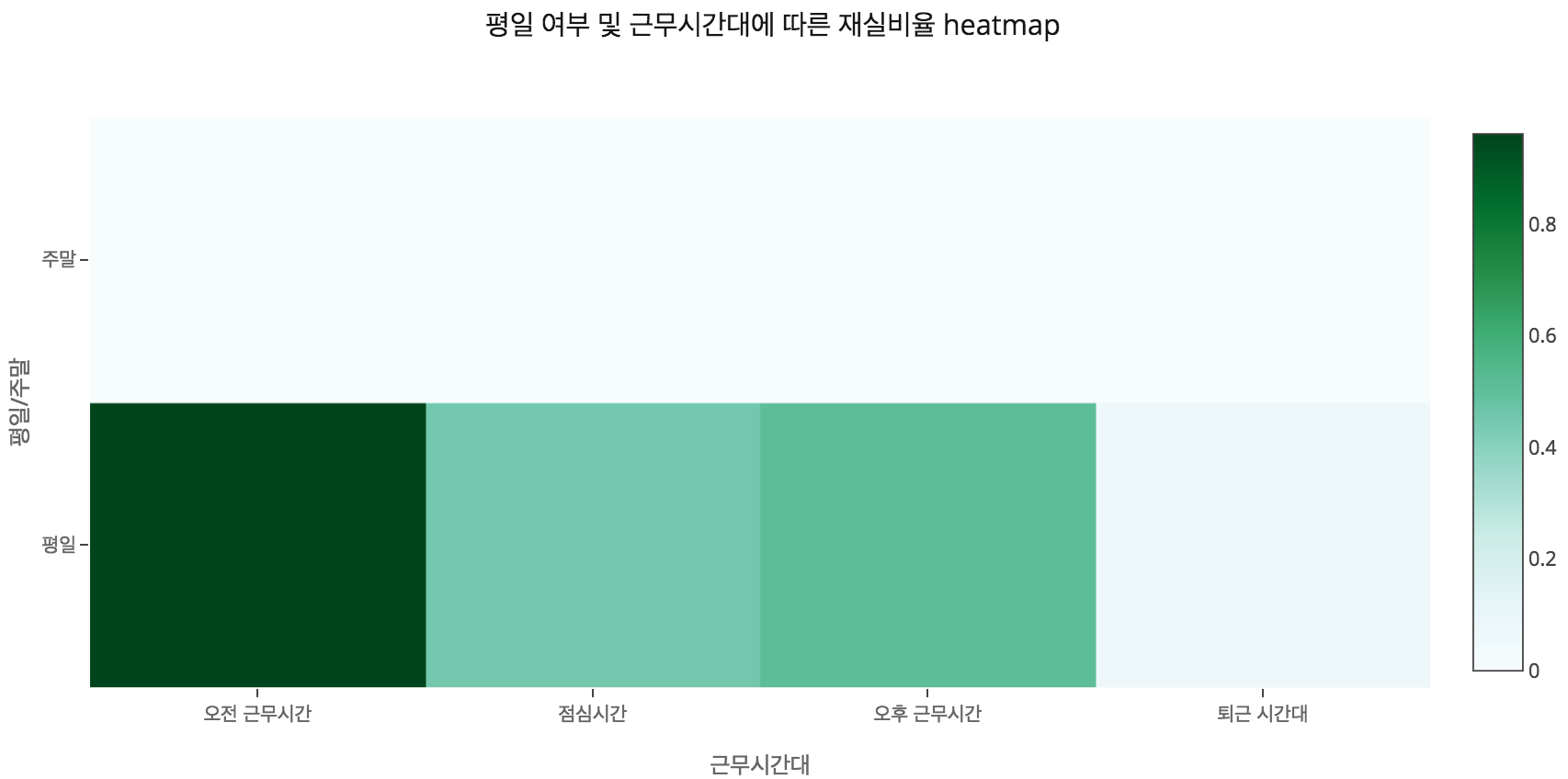
그렇다면 요일별로는 어떨까? Plot에서 무언가 이상한 점을 확인할 수 있었다. 바로 화요일과 수요일에 재실 비율이 유난히 낮다는 것이다. 이 회사는 화요일과 수요일에 조기 퇴근을 하는 풍습이라도 전해져 내려오는 것일까? 물론 그렇지 않다. 위에서 데이터 요약 파트에 명시하였듯이 training 데이터의 측정기간은 15.02.04(수) 17:51 ~ 15.02.10(화) 09:33이다. 즉, 수요일 오후 근무 시간대 끝물에 측정을 시작하여, 화요일 오전 근무 시간대 시작점에 측정을 종료한 것이다. 이에 따라 training 데이터만 보면 이 회사는 화요일과 수요일에 거의 출근을 하지 않는 것처럼 보이는 것이다. 만약 이 상태로 요일을 모델 학습에 사용한다면 우리의 모델은 화요일과 수요일의 경우 재실할 가능성이 낮아진다고 학습할 것이지만 이는 사실이 아니다. 따라서, 우리는 날짜를 요일 단위로 변환하지 않고, 평일과 주말의 구분만 이용하기로 하였다. 그 결과는 아래와 같다. 재실 비율이 제대로 측정된 월,목,금요일의 재실 비율보다는 소폭 감소하였으나, 크게 감소하지는 않았다. 또한, 평일 여부와 근무시간대를 이용하여 그린 heatmap에서 구간별로 재실 비율의 차이가 큰 것을 확인할 수 있었다. 따라서 시간대를 이렇게 두가지 방식으로 나눔으로써, 재실 여부 파악에 사용하기로 결정하였다.
Modeling
Feature Selection - Lasso Regression
위에서 EDA를 통해 우리는 Occupancy 예측에 온도(Temperature), 이산화탄소 농도(CO2), 습도 비율(Humidity Ratio), 평일/주말, 근무시간대라는 총 5개의 변수를 사용하기로 결정하였다. 이것만으로도 충분히 좋은 모델이 나올 수는 있으나, 종종 변수간의 관계는 일차적이지 않을 수도 있다. 독립변수 각각이 반응변수에 미치는 영향은 미미하나 그 상호작용은 큰 영향을 미칠 수도 있으며, 이차항이 관련이 있을 수도 있고, log 변환된 값이 관련이 있을 수도 있다. 따라서 이러한 관계를 고려한 변수들을 모델에 넣어주면 성능이 향상될 수 있다. 하지만, feature 갯수를 무작정 늘리면 training 데이터에 overfitting이 발생하여 모델의 예측력이 오히려 떨어지는 상황이 발생한다. 이를 방지하기 위해 feature selection을 해주어야하며, 다양한 feature selection 방법 중에서 우리는 Lasso Regression을 사용하기로 하였다.
Lasso regression은 L1 regularization 항을 추가한 회귀분석 방식이며, 그 특성으로 인해 예측에 상대적으로 불필요한 항의 계수값이 0으로 학습되어, 해당 변수를 사라지게 만든다. 우리는 각 변수의 제곱항, log변환항, 곱 변수항을 추가하여 lasso 회귀를 적용하였으며, 그 결과 선택된 변수는 아래와 같다.
CO2, TemperatureCO2, CO2CO2, CO2HumidityRatio, HumidityRatioHumidityRatio, log_Temperature, log_CO2, log_HumidityRatio, time_section_1(근무시간대), time_section_2, time_section_3, weekend(평일/주말), Occupancy
이제 이 변수들을 이용하여 모델을 설계하고자 한다.
Logistic Regression
가장 먼저 사무실의 재실 여부를 파악하기 위해 수행한 모델은 로지스틱 회귀 분석 모형이다. 이 모형은 이해가 쉽고, 성능이 꽤나 잘 나온다는 장점이 있다. 우리는 k=4인 k-fold cross validation을 통해 train 데이터의 25%를 validation set으로 사용하여 더욱 일반화된 모형을 설계하였다. 로지스틱 회귀분석은 각 관측치의 Occupancy가 1(재실 중)일 확률을 추정해주는데, 보통은 0.5의 threshold를 기준으로 추정된 확률값이 이보다 높으면 해당 관측치를 1로 분류한다. 우리는 모델의 성능을 더 높이기 위하여 25%의 cross validation set을 통해 f1 score를 max 시키는 최적의 threshold를 추정하였다. 그 결과, threshold=0.32일 때, train 데이터의 f1-score가 최대가 됨을 확인할 수 있었다. 다음은 이를 train과 test 데이터들에 적용한 결과이다.
| . | train | test1 | test2 |
|---|---|---|---|
| accuracy | 0.96 | 0.93 | 0.82 |
| f1 score | 0.91 | 0.90 | 0.50 |
위에서 확인할 수 있듯이. train과 test1 데이터에 대해서는 모델의 성능이 꽤나 좋았다. 하지만 test2 데이터에 대해서는 f1 score가 상대적으로 낮았다. 우리는 occupancy=1이 상대적으로 더 적은 불균형 데이터를 다루고 있기 때문에 f1 score가 높은 것이 중요한데, test2에 대하여 이를 달성하고 있지 못하므로 이를 해결해주고자 했다. 따라서 좀더 복잡한 stack 모델을 적용해보았다.
Stacking Model
모델을 stacking 하여 예측 성능을 높이는 것은 이미 kaggle 등의 데이터 경연대회에서는 하나의 정설처럼 여겨지고 있다. Stacking의 장점은 하나의 단일 모델이 가지고 있는 약점을 다른 모델들을 통해 보완하여, 모델들의 장점만 취할 수 있다는 점이다. 우리는 자체적으로 만든 stacking model을 이용하였으며, 이 모델은 xg-boost, random forest, gradient boosting, bagging, ada boost, mlp, logistic regression, extra tree model들이 두 개의 층에 걸쳐서 쌓여있는 형태이다. 이때 각각의 classifier마다 k=5인 k-fold cross validation을 통해 최적의 threshold를 설정해주었다. 모델의 자세한 구조는 우리팀의 영업 비밀이므로, 이 정도에서 생략하겠다. 최종적으로 stacking이 완료되면 각각의 모델들의 prediction 값이 데이터의 열로 추가되어 총 13개의 컬럼이 추가되는데, 이렇게 추가된 데이터를 다시 classifier에 넣어 최종 prediction을 수행한다.
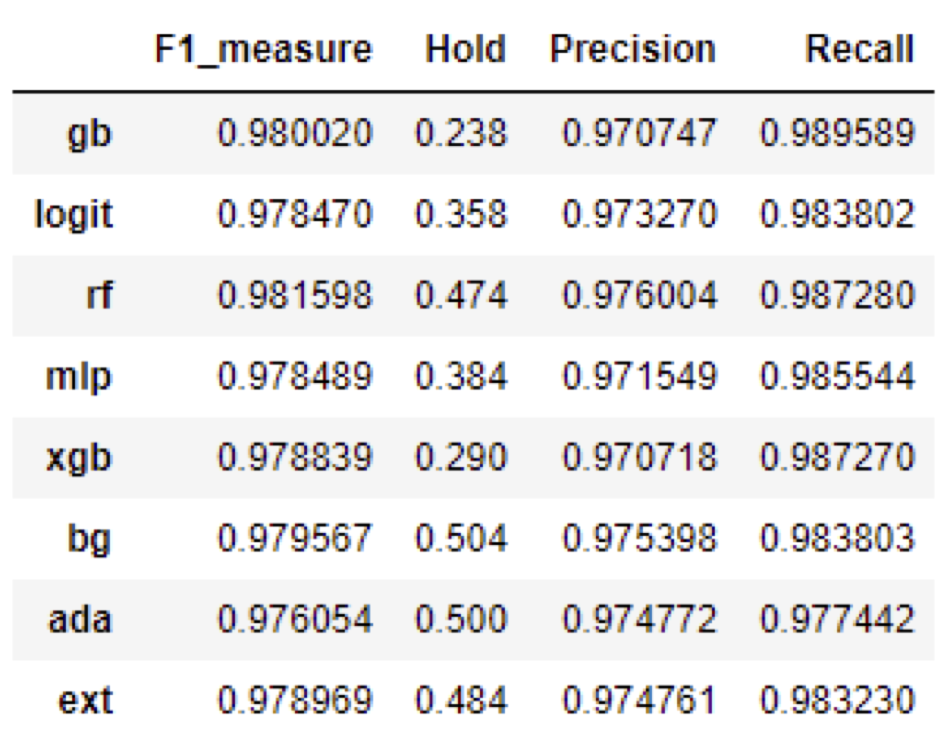 |
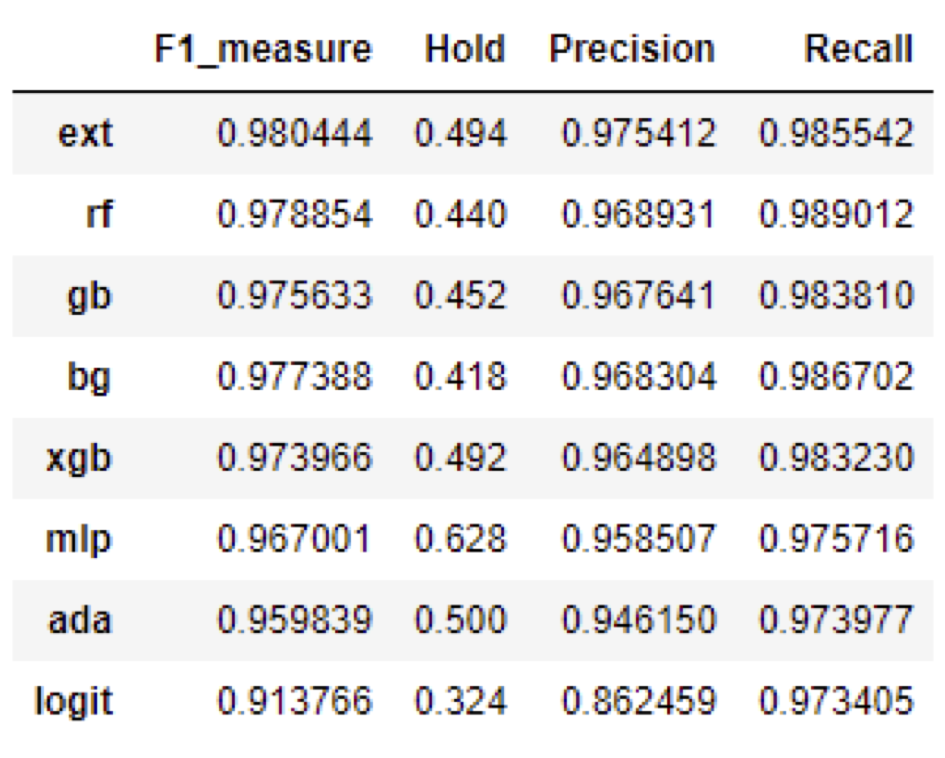 |
|---|---|
| stacking 최종 predict | 단일 모델 최종 predict |
위의 좌측 그림은 stacking model의 최종 classifier 후보 모델별로 cross validation set에 대한 f1-score 및 threshold를 구한 것이다. 우측 그림은 stacking을 사용하지 않고 단일 모델을 이용한 cross validation 결과이다. 동일 모델에 대하여 좌측이 더 좋은 경우도 있고 우측이 더 좋은 경우도 있으나, 최고의 성능을 내는 모델은 stacking을 한 뒤 랜덤 포레스트를 이용하여 분류한 모델이다. 따라서 우리는 이 모형을 test set에 적용해보고자 한다.
| . | train data | test1 data | test2 data |
|---|---|---|---|
| accuracy | 0.99 | 0.93 | 0.84 |
| f1 score | 0.99 | 0.90 | 0.59 |
로지스틱 회귀 모형의 결과와 비교해 보았을 때, 모든 데이터셋에 대하여 정확도 및 f1 score가 비슷하거나 높아진 것을 확인할 수 있다. 특히, 본래 목적이었던 test2 데이터에 대한 f1 score 증가가 달성되었다. 이 결과로 미루어 볼 때, stacking model이 단순 로지스틱 회귀 모형보다 일반화에 성공한 것으로 보인다. 다만, 그럼에도 여전히 test2 데이터의 f1-score는 그리 높지 않은데, 이는 EDA 과정에서도 설명하였듯이, test2 데이터의 형태가 train 및 test1 데이터의 형태와 조금 다른 양상을 띄고 있기 때문이라고 생각된다. 만약 training data가 더 커져서 test2 데이터와 같은 경우도 포함하게 된다면 예측력이 훨씬 높아질 것으로 보인다.
Conclusion
이 보고서를 통해 우리는 사무실에 사람이 재실하고 있는지 여부를 판단하는 모델을 설계해보았다. 이 모델을 사무실의 조명 관리 소프트웨어에 결합하면 실제 사람이 있는 공간에만 불을 밝힐 수 있게 되어, 전기를 절약할 수 있을 것이다. 또한 현재 자동 조명관리 시스템이 대부분 채택하고 있는 열적외선 또는 동작 인식 방식의 최대 단점인, 센서가 닿지 않는 기둥 뒤에 사람이 있는 경우에 조명을 끄는 불상사도 일어나지 않을 것이다. 이제 더 이상 불이 꺼지면 손을 허우적 거리며 센서에게 영역표시를 할 필요가 없다. 하지만 이 모델을 실제로 적용하기 위해서는 데이터를 다양한 날짜에 대해서 좀더 수집해야 할 것으로 보이며, 열적외선 또는 동작 감지 센서에 대한 컬럼도 추가해 주면 모델의 sensitivity를 상당히 올릴 수 있을 것이라 생각된다. 이 아이템을 통해 CEO로부터 칭찬을 받을 행복한 날이 오기를 기대해본다.