블랙박스 모델 뜯어보기
이 글은 interpretable machine learning를 정리한 글입니다. 해당 포스트에서 일부 추가 및 의역되거나 생략되는 내용이 있을 수 있습니다
intro
최근 많은 머신러닝 모델들이 개발되면서 모델의 예측력은 크게 향상되었고, 자율주행 등 실생활에 접목되는 사례가 늘어나고 있습니다. 하지만 운전/의료 등 인간의 생명과 직결된 것들에 머신러닝을 접목하는 게 때때로 꺼림칙하기도 합니다. 대부분의 강력한 머신러닝 모델은 블랙박스 모형이고, 과연 해당 모형이 내린 결론의 판단 근거가 인간이 예상하는 것과 같은지 알 수 없기 때문입니다. 때문에 머신러닝 모델을 뜯어보고자 하는 노력은 이전부터 지속되어왔고, 그 중 하나가 이 글에서 소개할 model-agnostic interpretation methods입니다.
Model-Agnostic Methods
model-agnostic 하다는 것은 학습에 사용된 model이 무엇인지에 구애받지 않고 독립적으로 모델을 해석할 수 있다는 의미입니다. 즉, 학습에 사용되는 모델과 설명에 사용되는 모델을 분리하겠다는 것입니다. 학습 모델과 설명 모델을 분리하는 것의 가장 큰 장점은 자율성입니다.분석가들은 기존에 자신들이 사용하던 모델들을 그대로 사용할 수 있으며, 어떤 모델을 사용했더라도 동일한 방식으로 해석할 수 있습니다.특히 비슷한 성능을 가지는 여러 모델 중 하나를 선택해야하는 상황이 발생했을 때, 모델을 해석한 결과를 동일한 기준으로 비교하여 객관적으로 더 나은 모델을 택할 수 있게 합니다.
model-agnostic한 방법 외에 기존에 많이 활용되던 방법은 크게 두 가지입니다. 첫째로는 해석 가능한 모델(ex.선형회귀)를 활용하는 것입니다. 하지만 다들 알다시피 이러한 방법들은 보통 예측력이 매우 낮으며, 이는 결국 이 해석에 대한 신뢰성의 문제로까지 이어집니다. 두번째로는 model-specific한 해석방법(ex.랜덤포레스트의 feature importance)를 활용하는 것입니다. 하지만 이는 같은 모델끼리는 비교가 가능할지 몰라도 서로 다른 모델과의 비교가 힘들어진다는 단점이 있습니다.
우리가 만들고자 하는 ‘모델에 구속받지 않는 해석 방법’은 크게 세 가지 지향점을 가지고 있습니다 (Ribeiro, Singh, and Guestrin 2016)
- Model flexibility : 해석 방식이 해석하고자 하는 모델의 종류에 상관없이 동일하게 동작해야 한다.
- Explanation flexibility : 해석의 형태가 자유로워야한다. 즉, 해석 결과를 다양한 방식으로 받을 수 있어야 한다.
- “모델 해석은 해줄게. 대신 bar plot 형태로만 볼 수 있고 넌 그냥 받기만 해.” 라고 말하는 모델은 쓰지 않겠다는 의미 같습니다.
- Representation flexibility : feature representation을 다르게 활용할 수 있어야한다. 예를 들어, 단어 분류기를 뜯어보는 과정에서 해석의 결과가 추상적인 word embedding vector라면 해석이 힘들 것이므로, 이를 다시 인간이 이해할 수 있는 단어로 보여줄 수 있어야 한다.(라고 조금은 추상적으로 써있습니다)
분석부터 해석까지
그럼 이제 데이터의 분석부터 해석까지의 일련의 과정을 그림을 통해 알아보겠습니다. 그림 역시 interpretable machine learning 깃헙 블로그에서 가져왔습니다.
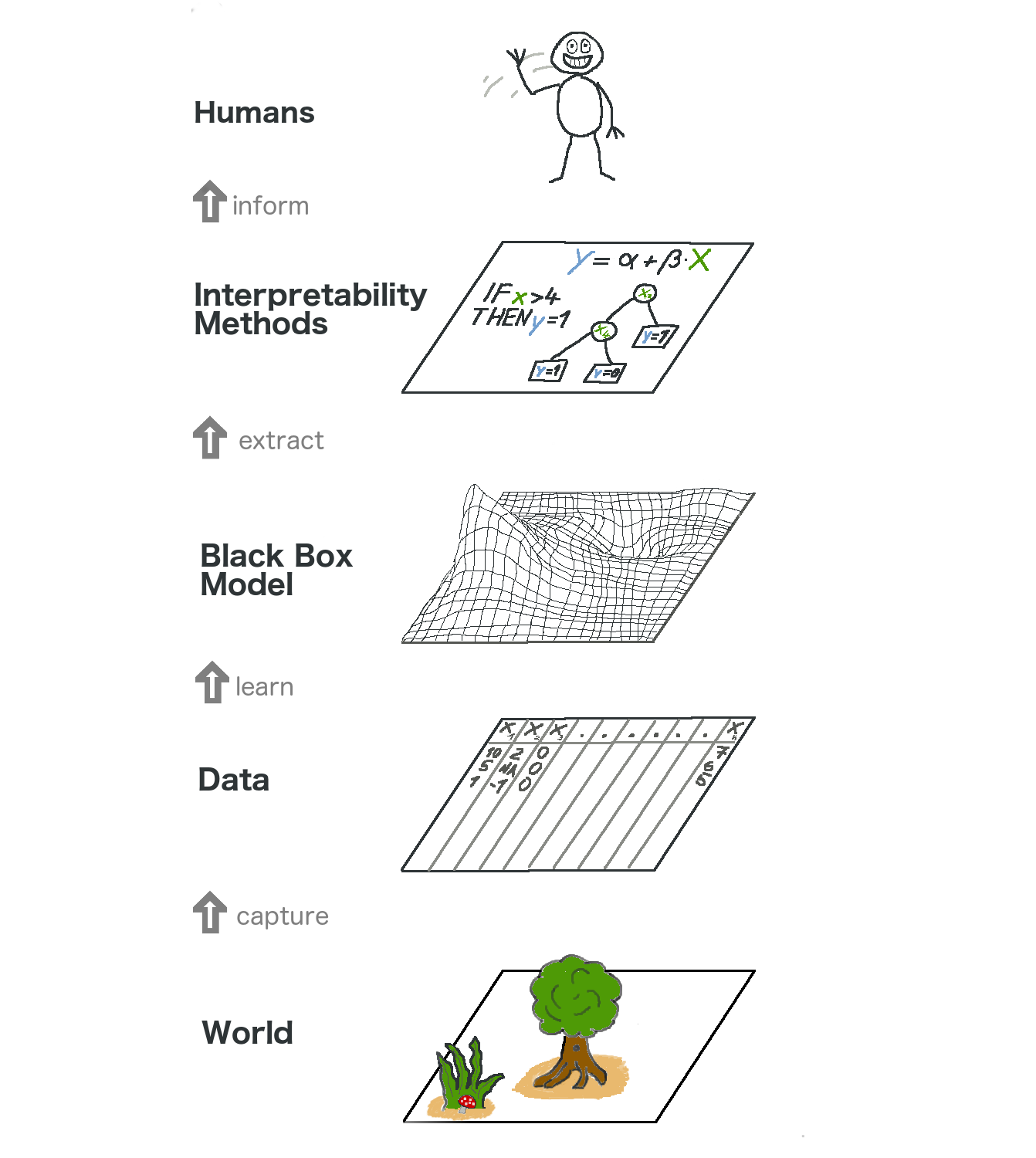
우리는 현실 속에 벌어지는 일들을 분석하기 위해서 측정 가능한 정보를 모아 데이터 형태로 변환한 뒤, 이를 머신러닝 모델(흔히 블랙박스)에 넣어 학습시킵니다. 잘 학습된 모델을 해석하기 위하여 앞서 설명한 model-agnostic interpretation methods를 포함한 여러 해석 방법을 이용하여 해석하며, 이를 최종적으로 우리 인간이 받아들이게 됩니다.
저자는 추가적으로 위의 일련의 과정을 통계학자와 머신러니스트(?)의 관점에서 비교합니다. 통계학자들은 일반적으로 데이터를 수집하는 과정에서 많은 이론적 기반을 사용합니다. 또한 블랙박스 모형을 뛰어넘고 바로 데이터의 해석 단계로 넘어갑니다. 머신러니스트도 데이터의 수집에 관심이 많지만 데이터 수집 이론보다는 방법에 조금 더 초점이 맞춰져있습니다. 또한 이들은 블랙박스 모형을 활용하며, 그 결과가 해석 과정을 생략하고 바로 인간에게 도달합니다. 하지만 model-agnostic interpretation methods를 활용하면 위의 그림에 나타난 일련의 과정을 모두 활용할 수 있으며 이는 통계학자와 머신러니스트의 거리를 좁히는 것이 된다고 저자는 말하고 있습니다. 다만, 이 예시는 조금 극단적이라고 생각하며 저자도 독자의 이해를 돕기 위해서 굳이 이러한 방식으로 설명한 것 같습니다. 통계학자와 머신러니스트 모두 데이터 사이언티스트라는 관점에서 위에 나타난 모든 단계를 엄밀하게 수행하기 위해 노력하고 있으며, 앞으로도 그럴 것이라 생각됩니다.
위의 그림에서 또한 주목해야 할 것은 인간이 현실세계를 데이터로 이해하기 위해서는 capture -> learn -> extract -> inform 이라는 네 번의 단계를 거쳐야한다는 것입니다. 이 단계들은 한 번씩 거칠 때마다 필연적으로 정보의 손실이 발생합니다. 이는 정말 긍정적으로 매 단계마다 20%씩 정보의 손실이 일어난다쳐도 인간은 데이터를 이용하여 현실세계를 41%밖에 이해하지 못한다는 것을 의미합니다. 따라서 아무리 좋은 모델링을 하고 이를 잘 해석했다고 해도, 이를 실제로 인간이 이용하는 데에는 항상 주의를 기울여야 하겠습니다.
outro
최근에 읽은 ‘플루토’ 라는 만화책에서는 “완벽한 인공지능이란 무엇인가”에 대해서 논하고 있습니다. 인간과 같은 의사결정을 내리는 인공지능이라면 종종 실수를 하는 것도 인간적이다라는 측면에서는 완벽한 것이 아닐까요. 인간 역시 현실을 capture -> learn -> extract 의 과정으로 이해한다면, 우리 역시 완벽하지 않을테니까요. 어쩌면 우리는 인간처럼 판단하는 모델을 만들겠다라고 시작한 출발점부터 잘못되었는지도 모릅니다. 블랙박스 모형을 뜯어서 해석하고, 다시 인간처럼 판단할 수 있게 모델을 수정하는 과정은 결국 우리 인간만큼 불완전한 의사결정을 할지도 모른다는 쓸데없는 철학적 고민을 해봅니다..
추후에 또 시간이 생긴다면 해당 깃헙 블로그에서 서술한 model-agnostic interpretation methods 각각에 대하여 설명해보도록 하겠습니다.