Hello World!
1. Introduction
-
NLP에서 LSTM은 매우 강력한 도구이며, 인간과 기계의 격차를 매우 줄여주었다.
-
이제 NLP는 LSTM을 사용하는 것이 표준처럼 되었다.
- 또한 auto-regressive convolutional model의 등장은 기존의 경쟁자들을 빠르게 앞질렀다.
- 기존 RNN처럼 sequential processing을 전체에 적용하지 않아도 다른 시간축까지 고려할 수 있게 되었다.
- 즉, efficient non-local referencing across time이 가능해졌다.
- 기존 RNN처럼 sequential processing을 전체에 적용하지 않아도 다른 시간축까지 고려할 수 있게 되었다.
-
하지만, convolutional model을 사용하는 것의 최대 단점은 높은 연산 복잡도와 수많은 parameter의 갯수였다.
- 따라서 Xception에서 처음 소개된 depthwise seperable convolutions를 nlp에 적용하여 효율성을 높이고자 한다.
2. Contributions
-
이 논문이 공표한 Slicenet은 크게 두 가지 특징을 가지고 있다.
- Xception에서 영감을 받은 이 논문은 depthwise seperable convolution layers를 stack하고, residual connection까지 적용한 형태이다. 이것은 이미지 처리분야에서는 이미 좋다고 증명된 방법이다.
- 또한 grouped convolution(sub-seperable convolutions) 를 적용하여, 자신들이 super-seperable convolution이라고 일컫는 것을 통해 더 많은 seperation이 가능해졌다고 주장한다.
- Bytenet과 같은 1D convolutional seq2seq 모델에서 쓰이던 filter dilation은 사용하지 않았다. 대신 seperability를 이용하여 그것보다 좋은 성능을 냈다.
2-1. Seperable Convolutions and grouped convolutions
-
depthwise seperable convolution은 grouped convolution과 inception family of convolutional network architecture의 결합.
-
즉, depthwise seperable convolution은 Depthwise Convolution과 Pointwise Convolution의 결합이다.
- Depthwise Convolution : 각 채널마다 독립적으로 convolution을 실행한다.
- Pointwise Convolution : 1-D convolution으로 여러개의 채널을 하나의 새로운 채널로 합치는 역할을 한다.
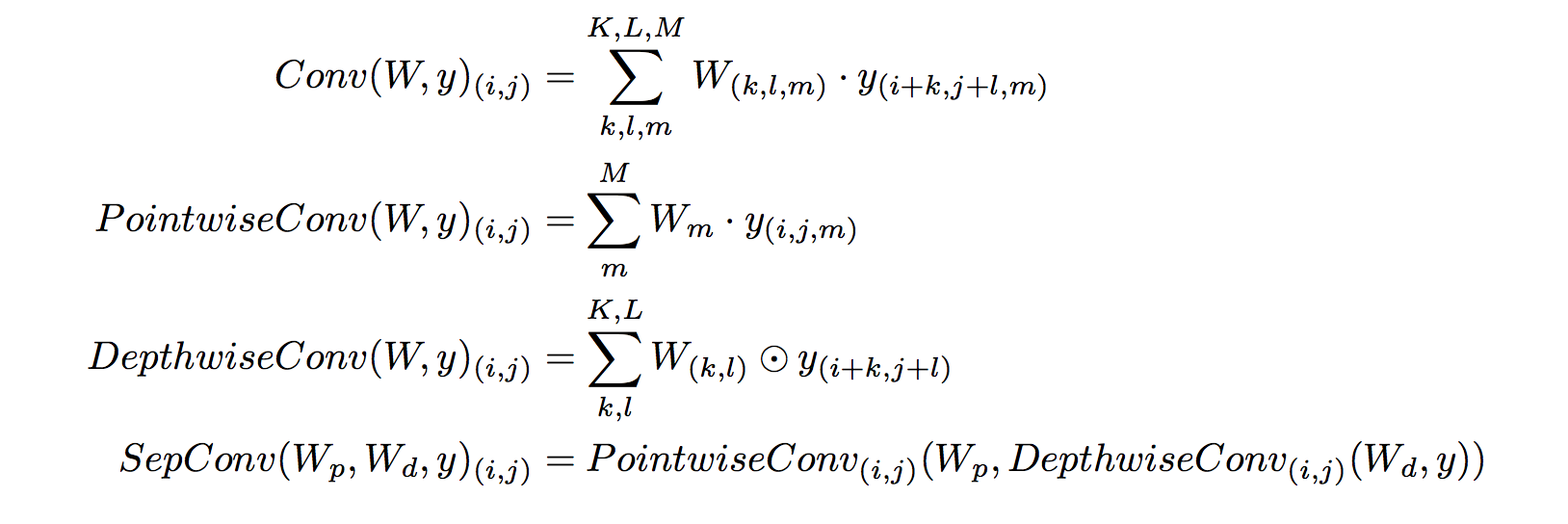
- 왜 depthwise seperable convolution을 하면 parameter 갯수가 줄어들까?
- ex) input Channel 10개, output channel 1개, 3*3 kernel size
- 기존 CNN : Parameter 90개 필요.
- DSC : Parameter 19개 필요.
- ex) input Channel 10개, output channel 1개, 3*3 kernel size
-
따라서 기존 CNN의 joint한 방법을, 2 개의 더 간단한 discrete 한 방법으로 구분하는 것이다.
-
input 데이터는 동일 채널 내에서는 관련이 많을 것이고(highly correlated spatial feature) 서로 다른 채널간에는 independent에 가까운 특성이 있을 것이다. 기존의 CNN은 각 채널의 filter가 이 두 개에 관한 역할을 한꺼번에 처리해야했다. 논리적으로 봤을 때 이 두가지는 구분되어야하는 것이고, depthwise seperable convolution이 바로 이것을 가능케한다.
- Grouped Convolution 은 기존 Convolution과 depthwise seperable convolution의 사이에 위치한다.
- input의 채널을 서로 안 겹치게 segmentation한 뒤, regular spatial convolution을 하고 concat한다.
- 참고 : https://blog.yani.io/filter-group-tutorial/
-
Depthwise seperable convolution은 동일한 파라미터 갯수로 더 잘 기능하는 것이 이미 증명되었다.
- 파라미터 갯수를 비교해보자(아래서 더 자세히 설명함)
- k = receptive field, c = channel
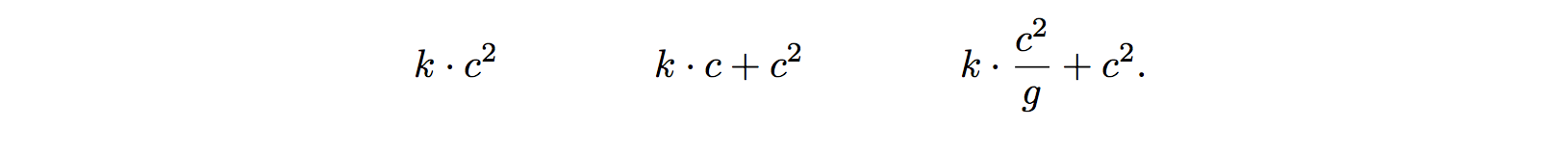
2-2. Super-Seperable Convolution
-
grouped convolution 을 개념을 비튼 것.
-
그룹 간에 정보의 전달이 불가하다는 특성이 있다.
- 이러한 문제를 해결하기위해 stack super-seperable convolutions in layer with co-prime g 를 이용한다.

2-3. Filter dilation and convolution window size
- dilation은 적은 parameter로 좀 더 넓은 범위를 본다.
- 참고 페이지
- Bytenet과 Wavenet에서 convolutional seq2seq autoregressive architecture의 key component로 지목했다.
- dilation은 그러나 stack이 되는 경우, deconvolution 과정에서 나타나곤 하는 checkboard artifacts와 비슷한 문제를 일으킨다.
- filter가 matrix의 전체 부분을 공정하게(동일하게) 관측하지 않기 때문에, 덜 중요하게 여겨지는 부분 즉, dead zone이 발생하게 된다.

- dilation factor를 서로소 관계인 수로 잡으면 괜찮겠지만, 그렇게 힘들게 쓰느니, 아예 쓰지 않는 것이 낫다.
- 역자 주) dilation = 3, stride = (2,2) 같은 느낌을 이야기하는 것 같다.
-
그렇다면, dilation의 본디 목적을 생각해보자. 공간적으로 더 넓은 receptive field를 가지면서 computational cost를 줄이고자 하는 것이 dilation의 본질이다.
- 이러한 dilation의 목적을 가장 잘 달성하는 방법은 사실 window size를 크게 하는 것이 최고이다.
- 문제는 그러한 경우 computational cost가 높다는 것이다.
- 우리의 depthwise seperable convolutions는 이 문제를 해결해주는 엄청난 모델이다.
- 왜냐하면 앞서 보았듯이, 기존 convolution에 비해 parameter 숫자가 매우 줄기 때문에 더 큰 window를 사용할 수 있기 때문이다.
- 뒤에서 dilation rate를 줄이는 것과 convolution window 사이즈를 키우는 것의 trade-off에서 설명하겠지만, Wavenet과 Bytenet의 주장과 달리 dilation이 우리 모델처럼 computational cost가 낮은 경우, 전혀 쓸모가 없다는 것을 발견하였다.
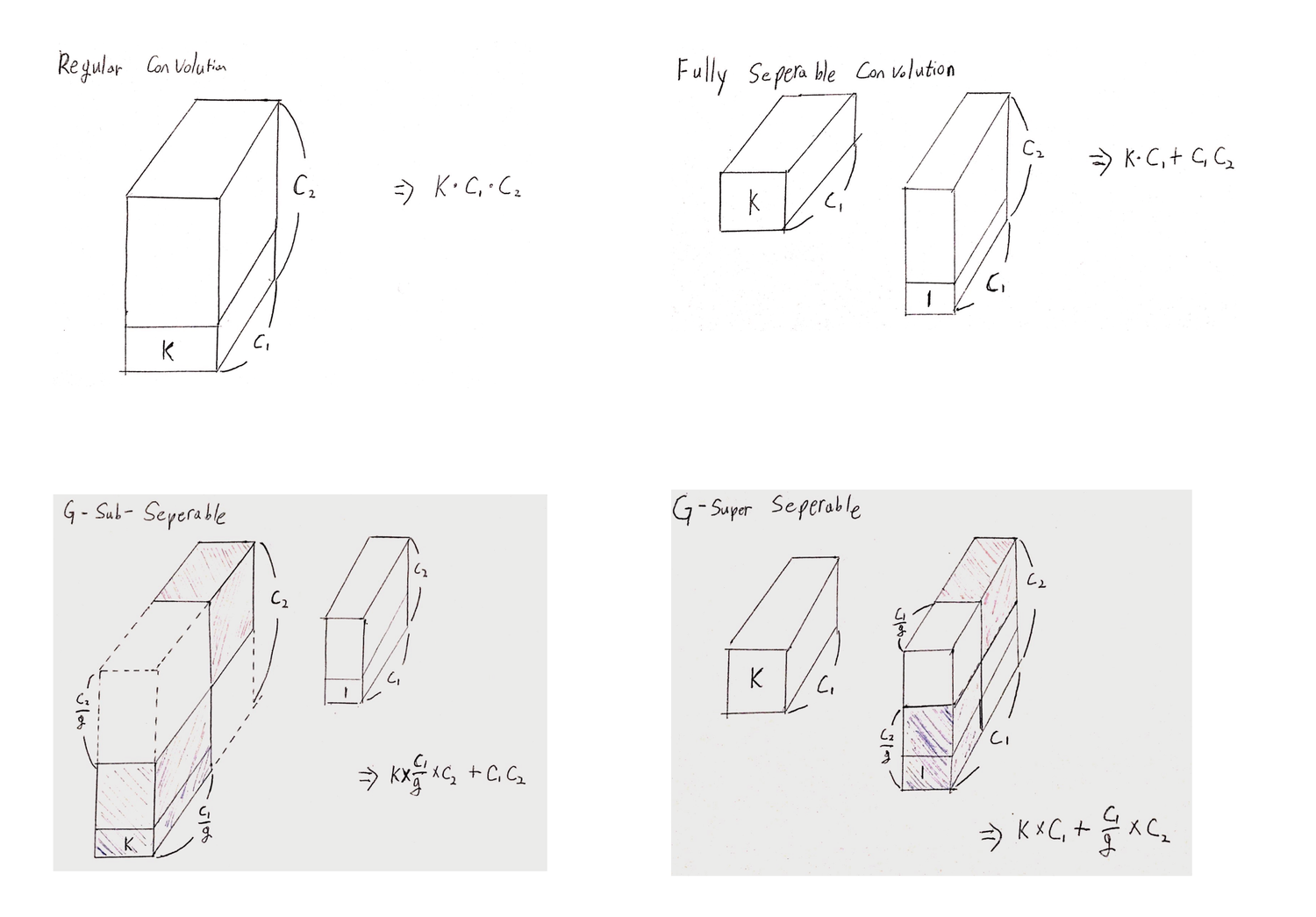
2-4. Convolutional model의 parameter 갯수 비교
- 이해를 돕고자 손수 손으로 그려보았습니다.
3. SliceNet architecture
-
대망의 모델SliceNet을 소개합니다아
-
ByteNet, WaveNet, PixelCNN에서 소개되었던 convolutional autoregressive structure를 그대로 사용한다.
- input과 output이 두 개의 서로 다른 네트워크로 embedding 되어, decode 되기 전에 합쳐진다.

3.1 Convolutional modules
-
[Sequence length, feature channels]의 shape을 갖는 tensor를 input으로 받아서, 같은 shape을 output으로 뽑는다.
-
Convolutional module은 4 개의 convolutional steps로 이뤄져 있다.
- Convolutional Step은 다음 순서로 진행된다.
- input에 대한 Relu activation
- Depthwise Seperable Convolution
- Layer Normalization
-
hidden unit h 개에 대한 표준정규화라고 생각하면 된다.
-
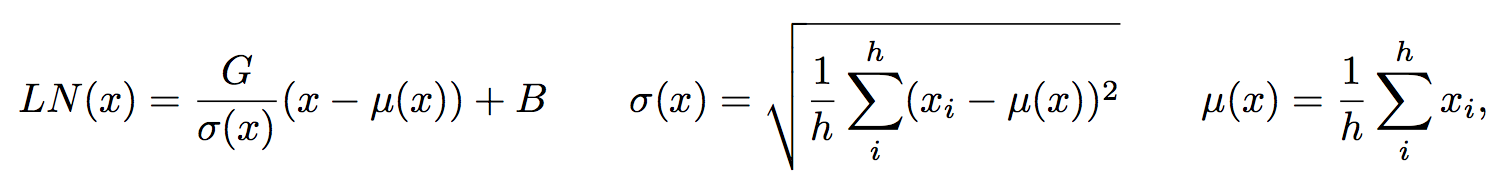
-
G와 B는 학습되는 스칼라값이다.
-
- Convolutional Step은 아래 수식으로 한 번에 정리할 수 있다.
- Convoluitonal Module은 convolutional step 네 개를 두 개의 skip connection과 함께 결합한 형태이다
- 이 Convolutional module을 다시 k 개 stack 하여서 사용한다.
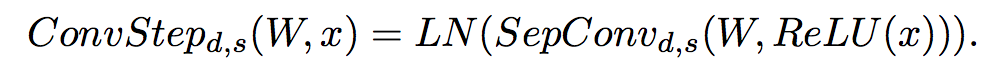
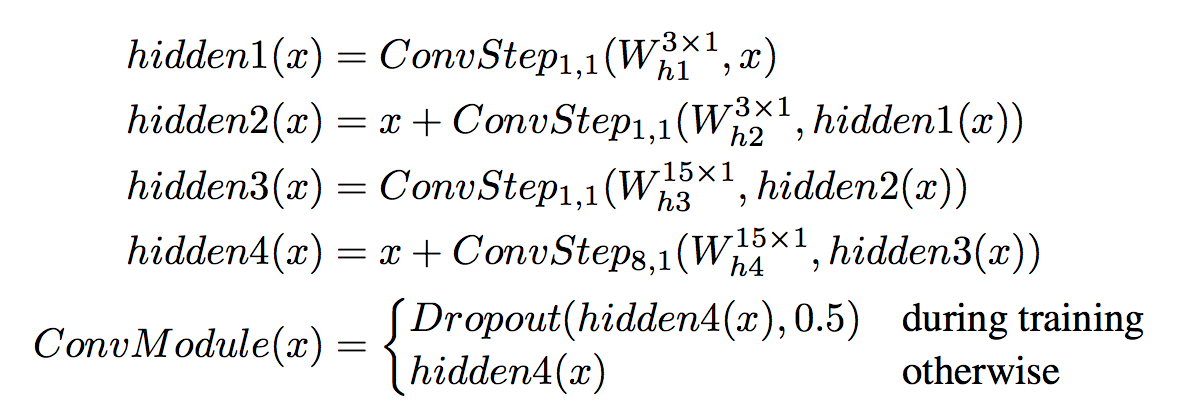
3.2 Attention modules
-
Attention을 위해서 Source([m,depth])와 target([n,depth])를 내적하여 사용한다.
- attention은 각 position의 feature vector의 similarity를 계산하고, depth에 따라 rescale 한다.
-
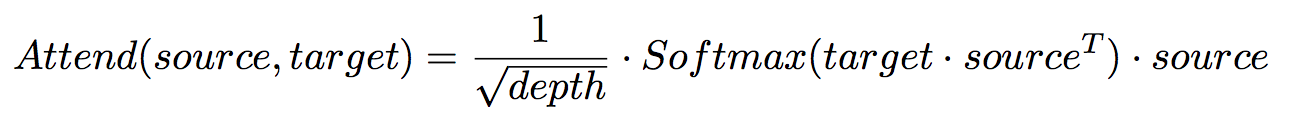
-
개인적인 추정 : m,n은 문장의 길이/ depth는 feature vector의 크기 같다.
-
-
attention이 positional한 정보까지 가질 수 있도록 하기 위해서 timing이라는 signal을 활용한다.
- 즉, source와 target 문장의 각 위치 간의 attention을 만들고, 문장 내에서 어느 위치에 있는지도 정보로써 주고자 하는 듯하다(역자 주)
- timing은 [k, depth]차원의 tensor이다. sine, cosine 함수를 서로 다른 빈도로 얽히게 한 형태이다.
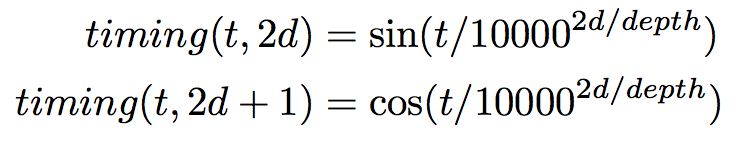
- timing은 다음 논문에서도 사용되었다.어려움 주의
- 이 논문의 attention mechanism은 target에 timing signal을 더하고, 두 번의 convolutional step을 거친 뒤, source에 attend하는 형태이다.
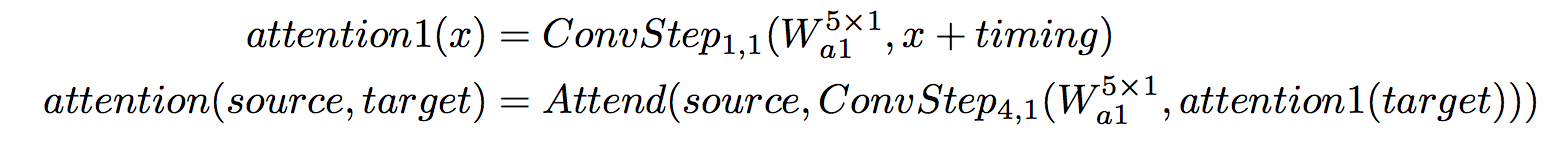
3.3 Autoregressive structure
-
앞서 말한대로 이 모델의 output은 autoregressive하게 만들어진다.
-
RNN과 달리 Autoregressive sequence generation은 이전에 생성된 output뿐만 아니라, 잠재적으로 이전에 생성되었던 모든 output에 의존하게된다.(long term dependency)
-
RNN을 이용한 Neural Machine Translation(NMT)에서 attention을 이용하여 long term dependency를 갖게 만드는 경우, 성능이 크게 향상된다는 사실은 기존에 알려져있었다.
-
우리의 CNN은 다른 경우보다 더욱 큰 receptive field를 가질 수 있으므로, 자연스럽게 long term dependency를 갖게 된다.
3.4 나머지
-
Input Encoder, IOMixer, Decoder에 대한 설명은 아래 수식으로 대체한다.
-
Output Embedding은 단순히 learning-embedding look-up을 수행한다.

4. Related Work
-
Machine Translation은 RNN with LSTM cells를 이용한 seq2seq model을 통해 매우 큰 성취를 거뒀다.
- 하지만 RNN의 특성상 한 번에 한 단어 vector만 봐야하므로 전체의 긴 문장도 한 단어씩밖에 못 읽기 때문에, 번역의 성능을 저하시키는 원인이었다.
- RNN에서는 이것을 Attention을 이용하여 극복하였다.
-
우리의 SliceNet은 이와 비슷한 기능을, 위에서 언급한 대로 좀더 간결하게 만들었다.
- 기존에 CNN을 이용한 다양한 word-level NMT들이 연구되었고 좋은 성능을 거뒀지만 한계점이 있었다.
- output을 뽑기 위해, 맨 위층에 RNN을 사용했었다.
- 여기에 사용된 RNN은 fixed size를 가지고 있었기 때문에, 여기에 넣기 위해서는 CNN의 최종 output도 fixed size로만 나와야 했다.
- 즉, 긴 문장이든 짧은 문장이든 같은 크기로 embedding 되어야했기 때문에 손실이 발생하였고, 이는 Attention 없이 RNN만 이용한 초창기 NMT 모델과 비슷한 문제를 갖고 있었다.
- 위와 같은 병목현상을 없앤 CNN 모델이 그 이후 나오기 시작했다.
- 대표적으로 WaveNet에서 소개되고, ByteNet에서 사용된 모델은 recursion을 버리고, left padded convolution을 사용했다.
- 효과는 강력했고, SliceNet도 위와같은 모델을 차용했다.
5. Experiment
- 우리는 크게 두 가지의 질문에 대한 실험을 했다.
- ByteNet의 convolution을 우리 depthwise convolution 으로 바꾸면 어떻게 될까?
- convolution window size를 키우는 대신 dilation을 줄이면 어떠한 trade-off가 발생할까?
- 부가적으로 두 개의 실험도 했다.
- Depthwise Seperable보다 조금 더 regular convolution에 가까운 모델을 쓰면 어떻게 될까?
- Depthwise Seperable Convolution을 g-sub-seperable convolution으로 교체
- Depthwise Seperable과 우리가 새로 만든 Super-sub-seperable 간의 성능 비교
- Depthwise Seperable보다 조금 더 regular convolution에 가까운 모델을 쓰면 어떻게 될까?
-
WMT English to German translation task 수행.
-
tokenization을 위해, Sennrich와 동일한 subword unit을 이용한 tokenization 수행.
-
아래와 같은 결론이 도출되었다.
-
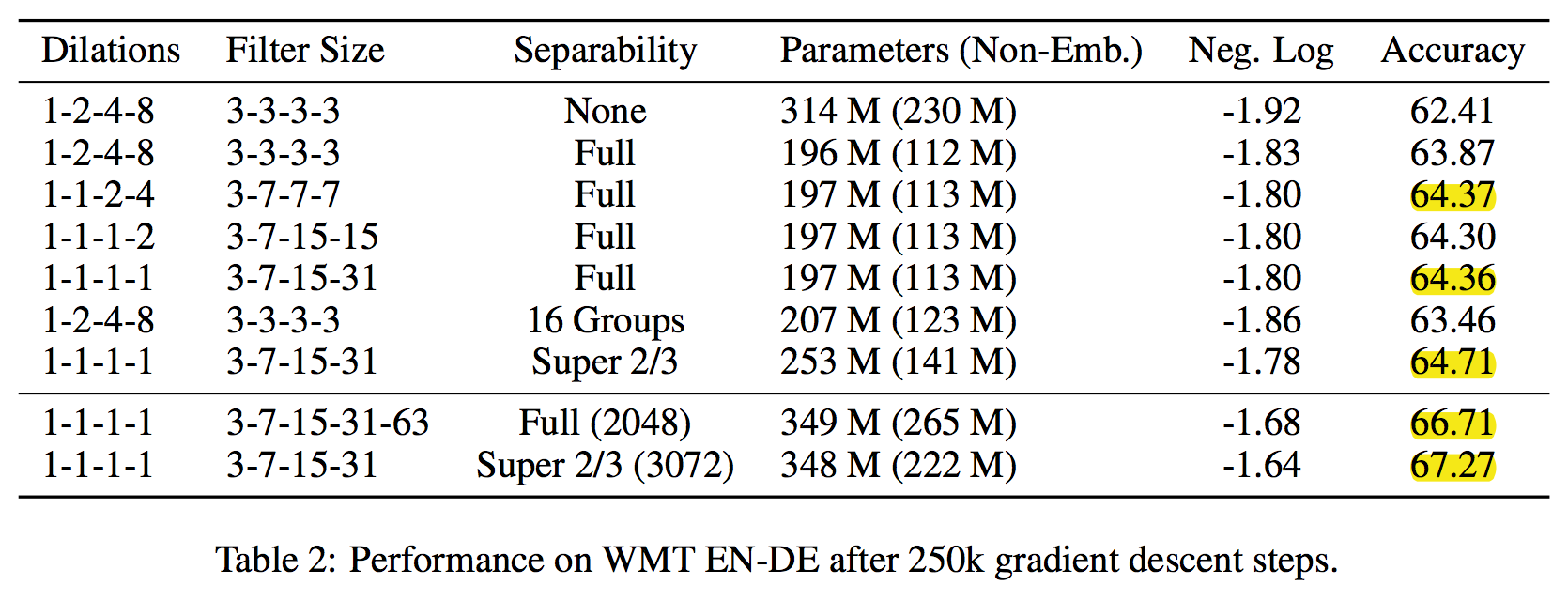
- Depthwise seperable convolution은 Bytenet과 같은 모델에서 사용한 regular convolution을 확실히 뛰어넘었다.
- 더 정확하고, 더 빠르고, 파라미터가 덜 필요하고, 더 적은 리소스로 돌릴 수 있다.
-
Full Depthwise Seperable convolution이 g-sub-seperable convolution보다 낫다. 그룹의 갯수를 낮춰서 depthwise seperable convolution에 가까워질수록 성능이 좋았다.
-
Depthwise Seperable Convolution을 이용하여, 리소스가 허락하는 수준까지 window size를 키우는 것이 dilation을 사용하는 것보다 훨씬 좋았다. Dilation은 불필요하다.
- 우리가 새로 소개한 super-seperable convolution이 괄목할만한 성능의 향상을 보인다.
-
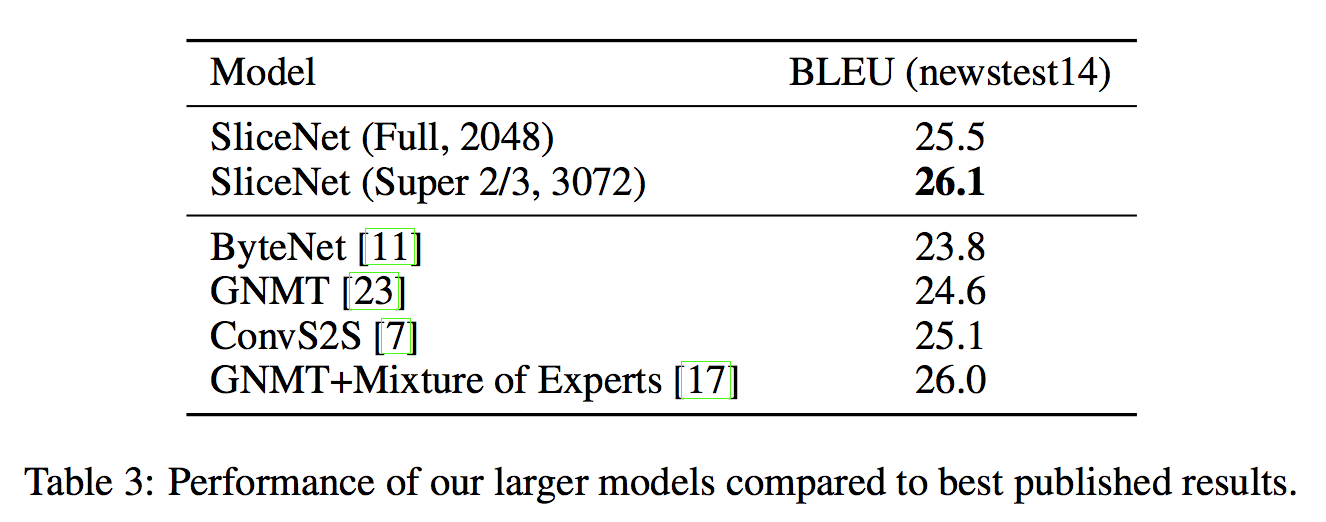
- 또한 더 깊은 feature depth를 갖는 task에 대해 실험한 결과, 아래의 state-of-art 결과가 도출되었다.
5.1 Conclusions
-
우리 모델은 앞선 state-of-art 와 ByteNet을 이겨버렸다.
- 특히 ByteNet보다 두배 적은 파라미터와 점곱 연산을 했다.
-
또한, dilation은 불필요하고, depthwise seperable convolution을 사용하여 window size를 키우는 게 낫다.
- 더불어, 우리가 소개한 새로운 super-seperable convolution은 depthwise seperable보다도 낫다.
-
마지막으로 우리의 모델을 최근 Xception과 MobileNets가 만들어온 trend의 계보를 잇는다
- 기존에 CNN을 기반으로 한 모든 모델들은 우리의 depthwise seperable convolution을 이용하여 성능 개선을 할 수 있다.