0. Abstract
-
2015년 논문이라 조금 옛날 얘기하는 느낌이 들 수도 있음을 미리 말씀드립니다.
- Neural Machine Translation(NMT) 문제에서 attentional mechanism은 최근에서야 조금씩 쓰이고 있다.
- 하지만, 어떤 attention 구조가 NMT에서 유용한지는 연구된 바가 없다.
- 따라서 이 논문에서는 global attention과 local attention 간의 성능을 비교해보고자 한다.
- 이것으로 BLEU score 기준, state-of-the-art(SOTA)를 달성했다.
1. Introduction
- NMT가 왜 매력적인가?
- 도메인 지식이 적어도 되며, 아이디어 자체가 간단하다.
- 보통의 Machine Translation(MT)과 달리, NMT는 상대적으로 적은 memory footprint만 쓴다.
- Standard MT는 수많은 phrase table과 language model을 저장해두어야 했다.
- NMT는 end-to-end로 학습되며, 문장 길이와 무관하게 쓸 수 있어서 일반화가 가능하다.
- Attention은 왜 매력적인가?
- attention은 서로 다른 modality 간에 연결을 지을 수 있다는 점에서 최근에 매우 유명해졌다.
- 예를 들어 speech to text, picture to text etc.
- (이때만 해도) 저자들이 아는 선에서 NMT에 attention을 적용한 예시가 없었다.
- attention은 서로 다른 modality 간에 연결을 지을 수 있다는 점에서 최근에 매우 유명해졌다.
- 따라서 저자들은 두 개의 attention based NMT 모델을 제안한다.
- global approach : 모든 source word가 attended 되는 모델
- local approach : 일부의 source word가 attended 되는 모델
- hard and soft attention model의 합성으로 생각해도 좋다.
- hard attention 과 달리, local attention은 differentiable하다
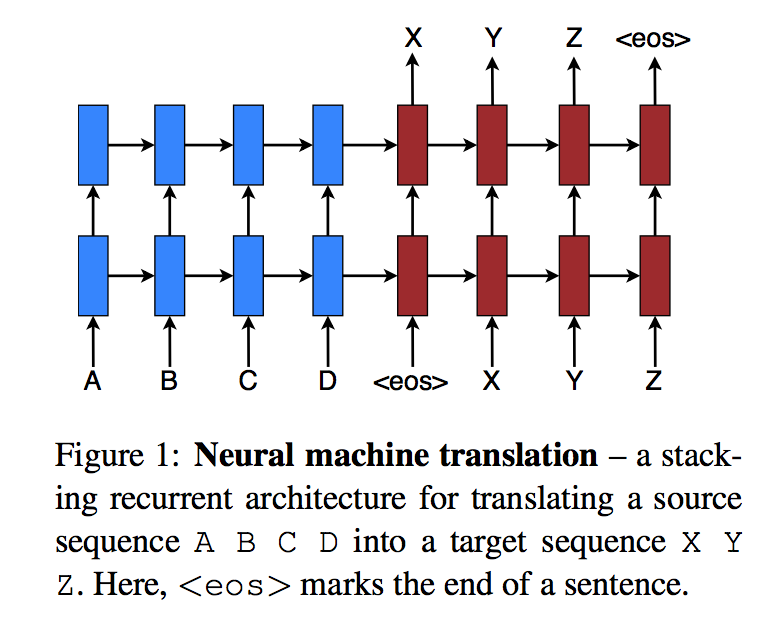
2. Neural Machine Translation
-
NMT는 조건부확률 p(y x)를 모델링하는 뉴럴넷이다. - y는 target sentence, x는 source sentence
- NMT의 가장 기본적인 형태는 encoder와 decoder로 구성된다.
- encoder : source sentence를 대표하는 s 벡터를 만드는 과정
- decoder : target 단어들을 하나씩 순서대로 만드는 과정
- \[log { p(y|x) } =\sum _{ j=1 }^{ m }{ \log { p({ y }_{ j }|{ y }_{ <j },s) } }\]
- 가장 일반적으로 decoder로 사용되는 건 RNN이지만, 그 형태는 논문마다 약간씩 다르다.
- Kalchbrenner and Blunsom : 일반적인 RNN 사용, encoder로 CNN 사용.
- Sutckever and Luong : LSTM을 쌓아서 encoder와 decoder로 사용.
- Cho and Bahdanau : GRU를 이용한 encoder and decoder 사용.
- decoding을 수식으로 나타내면,
- \[p({ y }_{ j }|{ y }_{ <j },s) = softmax(g({h}_{j}))\]
- h는 RNN hidden unit
- \[{h}_{j} = f({h}_{j-1},s)\]
- 위에 나열된 사람들 중 Bahdanau와 Jean을 제외한 사람들은 s를 처음에 decoder의 hidden state를 initialize 할 때 한 번만 사용.
- Bahdanau와 Jean은, 그리고 이 논문은 s를 전체의 번역 과정에서 사용.
- 이것이 attention mechanism이다.
- 이 논문에서는 NMT model로 stacking LSTM architecture를 사용한다.
3. Attention-based Models
- 이 논문의 attention-based model은 global과 local로 크게 구분된다.
- 두 개의 차이는 모든 source position을 고려하는지의 여부이다.
- 두 개 모두 stacked LSTM의 t번째 hidden state \({h}_{t}\)를 input으로 받는다.
- 목적은 문맥 백터 \({c}_{t}\)를 뽑아내기 위함이다. \({c}_{t}\)는 target 단어 \({y}_{t}\)를 맞추는데에 필요한 source 쪽의 정보를 저장한다.
- 두 개의 모델은 이러한 \({c}_{t}\)를 뽑아내는 방법에서의 차이이다.
-
위 두 벡터를 concat하여 새로운 attentional hidden state vector \(\widetilde { h }\)를 뽑아낸다
- 이를 이용하여 target 단어를 생성하는 과정은 아래와 같다.
- \[{ \widetilde { h } }_{ t }=tanh({ W }_{ c }[c_{ t };h_{ t }])\]
- \[p({ y }_{ t }|{ y }_{ <t },x)=softmax({ W }_{ s }{ \widetilde { h } }_{ t })\]
3.1 Global Attention
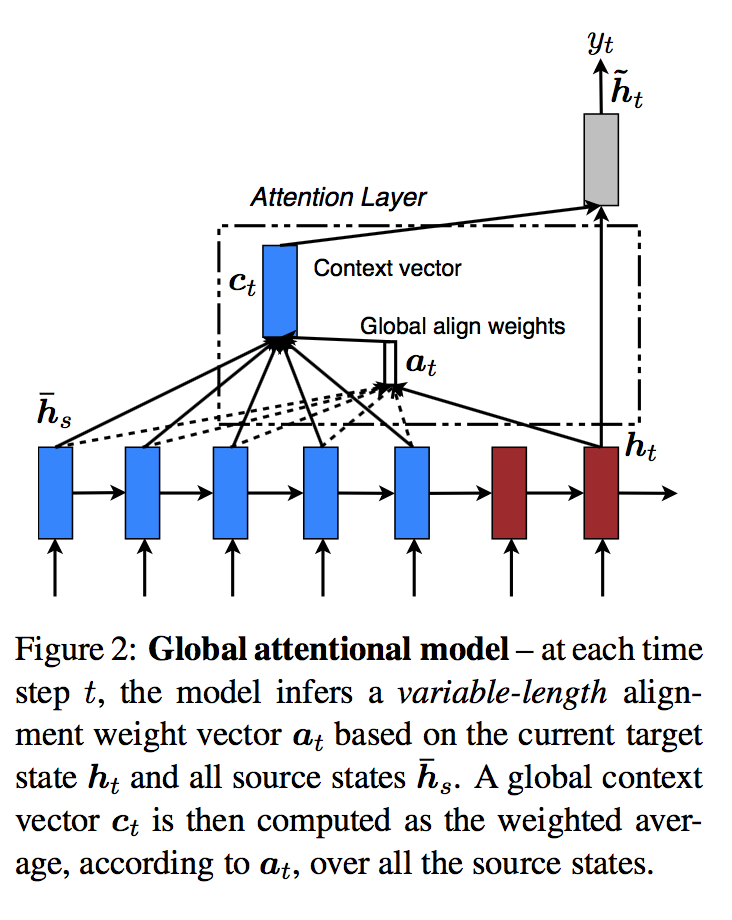
-
\({c}_{t}\)를 뽑아낼 때, encoder의 모든 hidden state를 고려한다.
- 이를 위해서는 alignment vector \({a}_{t}\)가 필요하다.
- \({a}_{t}\)는 source 문장의 timestep과 동일한 크기를 가진다.
- 현재의 target hidden state \(h_{ t }\)와 source의 hidden state \({ \bar { h } }_{ t }\)를 비교하여 유도된다.
- \[{ a }_{ t }(s)=align({ h }_{ t },{ \bar { h } }_{ s })=\frac { exp(score({ h }_{ t },{ \bar { h } }_{ s })) }{ \sum _{ { s' } }^{ }{ exp(score({ h }_{ t },{ \bar { h } }_{ s' })) } }\]
- score는 content-based 함수이며, 세 가지 방식으로 유도될 수 있다.
- \[score({ h }_{ t },{ \bar { h } }_{ s })=\begin{cases} { h }_{ t }^{ T }{ \bar { h } }_{ s } \\ { h }_{ t }^{ T }{ { W }_{ a }\bar { h } }_{ s } \\ { W }_{ a }[{ h }_{ t }^{ };{ \bar { h } }_{ s }] \end{cases}\]
- 이들이 앞서 attention-based 모델을 만들 때는 location-based 함수를 사용했었다.
- \[{ a }_{ t }=softmax({ W }_{ a }{h}_{t})\]
- 즉, alignment score를 target hidden state의 가중평균으로 만들었다.
- context vector \({c}_{t}\)는 source hidden state의 가중평균으로 만들어진다.
- 위에서 구한 alignment vetcor를 이용한 가중평균
- 이 논문의 모델은 기존에 Bahdanau 가 쓴 모델과 비슷하지만 차이가 있다.
- 이 논문은 stacked LSTM layer의 맨 위층의 hidden state를 사용한다(encoder, decoder 모두)
- 이와 달리 Bahdanau는 bi-directional encoder의 hidden state와 non-stacked uni-directional decoder의 hidden state를 사용했다.
- Bahdanau 대비, computational path가 단순하다.
- score를 구할 때, 이 논문은 세 가지를 시험했고, Bahdanau는 한 가지(concat)만 사용하였다.
- 이 논문은 stacked LSTM layer의 맨 위층의 hidden state를 사용한다(encoder, decoder 모두)
3.2 Local Attention
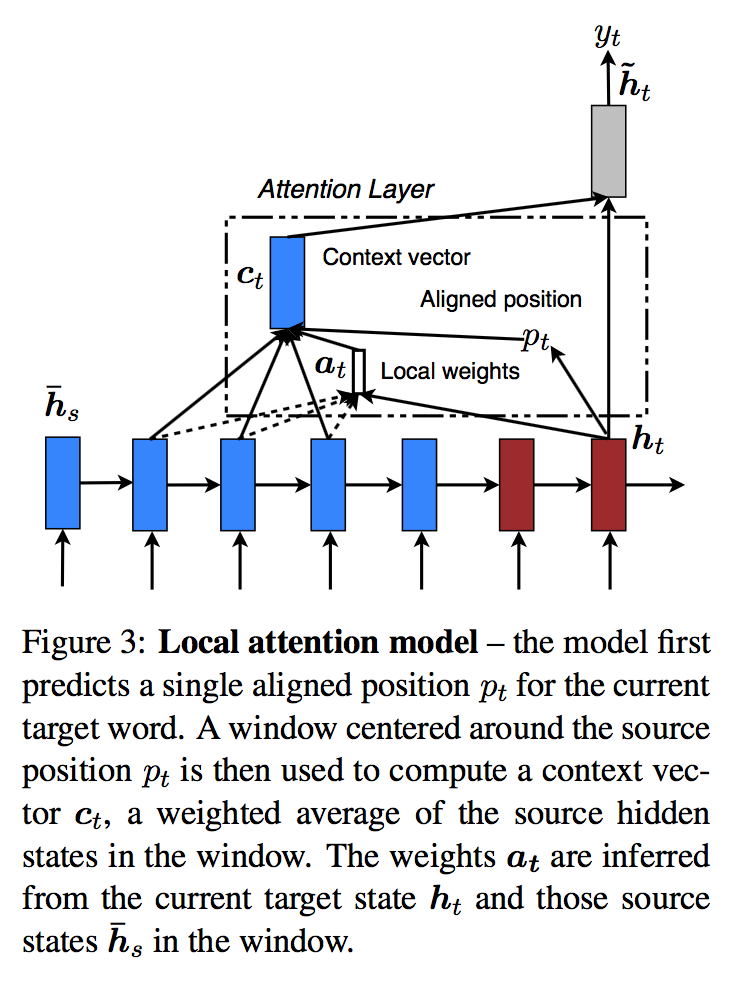
- global attention은 전체 source word를 attend했다.
- 이는 resource가 많이 필요하고, 긴 문작 혹은 문맥을 해석하는 데에 비실용적이다.
- ex) 문단 혹은 글
- 이는 resource가 많이 필요하고, 긴 문작 혹은 문맥을 해석하는 데에 비실용적이다.
- 따라서 target 단어당, 일부의 source position만 보는 모델을 생각했다
- 그것이 local attention이다.
- 이 모델은 Xu가 주장한 tradeoff between the soft and hard attention model에서 영감을 받았다.
- Soft attention은 global attention과 동일하다.
- input image의 모든 부분에 weight를 준다.
- Hard attention은 한 번에 attend할 input 이미지의 한 부분을 정한다.
- 빠르지만, 미분불가하고 분산감소, 강화학습 등 복잡한 기술을 많이 사용해야한다.
- Soft attention은 global attention과 동일하다.
- 이 논문의 local attention은 문맥의 일부(window)만 고려하며 미분 가능하다
- soft attention보다 빠르며, hard attention보다 쉽다.
- 방법은 아래와 같다.
- t시점의 target 단어에 대하여, aligned position \({p}_{t}\)를 정한다.
- \({c}_{t}\)는 \([{p}_{t}-D, {p}_{t}+D]\) 사이에 있는 source 단어들의 가중 평균이다.
- D는 실험적으로 정한다.
- 따라서 이제 \({a}_{t}\)는 고정된 크기(2D+1)를 갖는다.
-
\({p}_{t}\)를 찾는데에는 두 가지 방법이 쓰였다.
- 1. Monotonic alignment(local-m)
- \({p}_{t}=t\)로 단순하게 생각.
- 같은 위치에 있는 단어끼리 연관이 클 것이란 아이디어
- \({a}_{t}\)는 global attention 때와 동일한 방법으로 생성
- 2. Predictive alignment
- \[{ p }_{ t }=S\cdot sigmoid({ v }_{ p }^{ T }tanh({ W }_{ p }{ h }_{ t }))\]
- \({ W }_{ p }, { v }_{ p }\) 는 학습되는 변수. S는 문장의 길이
- 이에 따라, \({ p }_{ t }\in [0,S]\) 가 도출된다.
- 더불어, 해당 \({ p }_{ t }\)를 기준으로 gaussian적으로, 주변단어들이 의미를 가질 것이라 생각하여
- \({ a }_{ t }(s)=align({ h }_{ t },{ \bar { h } }_{ s })exp(-\frac { { (s- }{ p }_{ t })^{ 2 } }{ 2{ \sigma }^{ 2 } } )\)을 이용한다.
- 1. Monotonic alignment(local-m)
3.3 Input-feeding Approach
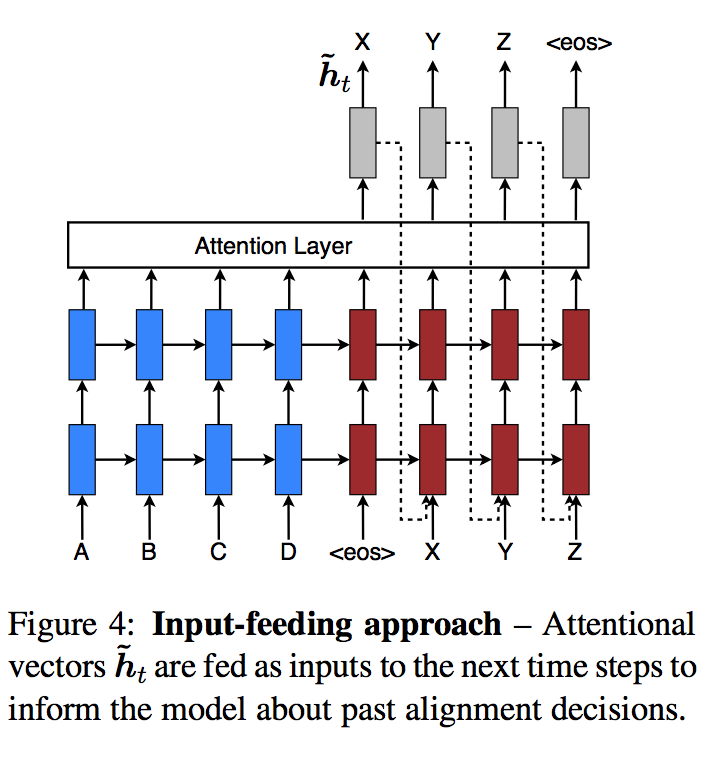
- 이 논문의 모델에서는, atttentional decision이 독립적으로 이뤄진다.
- 하지만, 일반적인 machine training에서는 어느 단어가 번역이 완료되었는지 지속적으로 체크한다.
-
따라서 과거의 alignment information이 지금의 alignment decision에 고려되게(jointly) 만들어야한다.
-
이를 위하여 attentional vector \({ \widetilde { h } }_{ t }\)를 다음 시점의 input과 concat시켜서 넣어준다.
- 이것의 목적은 다음 두가지이다.
- 이전의 alignment choice를 알게 하고 싶다.
- 수평&수직적으로 deep한 network를 만들고자한다.
4. Evaluation
-
WMT translation tasks between English and German 으로 평가하였다.
-
case-sensitive BLEU로 평가됨
- 두 개의 BLEU 사용
- tokenized BLEU
- NIST BLEU
-
언어별로 자주 쓰이는 5만개 단어만 사용.
- 1000개의 cell과 1000개의 차원을 가진 LSTM 사용.
- [-0.1,0.1]로 모수 initialize
- 10 개의 epoch을 SGD 이용 학습
- learning rate를 1로 시작, 5 epoch 돈 뒤부터 이등분함.
- mini batch size 128
- gradient의 norm이 5 넘을 때마다 normalize
- dropout 모델의 경우, 12번의 epoch 돌고, 8 이후부터 learning rate 이등분.