1. Intro
- CNN을 이용하여 문장의 label을 분류하는 모델입니다.
- word2vec을 이용합니다.
- word2vec은 단어의 semantic한 특성을 공간에 표현합니다.
- 따라서 의미적으로 비슷한 단어가 가까운 공간에 위치하며, 단어의 의미적인 연산도 가능해집니다.
- 이 논문은 word vector로 기존에 학습되어 공개된 vector를 그대로 활용하기도 하고, back propagation 과정에서 update 시키기도 합니다.
2. Model
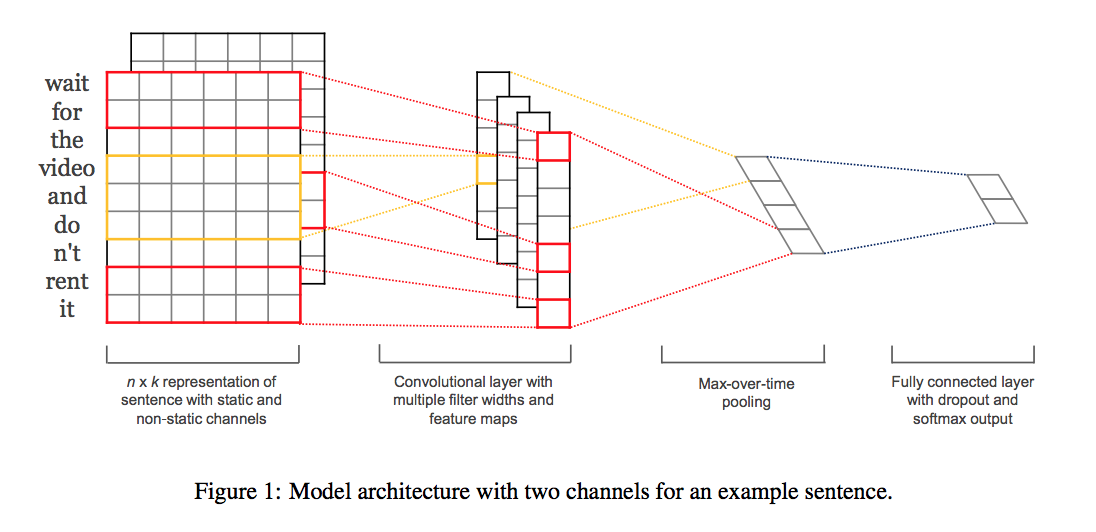
- n개의 단어를 가진 문장이 있으며, 이를 구성하는 단어 각각은 k차원 vector로 표현된다.
- k차원 vector는 word2vec으로 표현된 단어의 vector이다.
- 위 둘을 합쳐서 한 문장을 n x k의 matrix로 표현한다.
- window size h(단어 갯수)를 설정한다.
- \(c_i = f(w \cdot x_{i:i+(h-1)} + b)\) 의 convolution 연산을 해준다.
- 이때 함수 f는 non linear한 activation function(예를 들면 tanh)이다.
- 위의 convolution 연산의 결과로 각 window size별 filter의 갯수만큼 feature map이 나온다.
- window size를 바꿔가면서 여러 개의 feature map을 생성한다.
- 이렇게 만들어낸 각 feature map을 max-over-time-pooling한다.
- 이를 통해 각 filter 별로 가장 중요한 특성을 뽑아내자는 의미이다.
- 즉 하나의 window size별 filter를 여러번 사용하고, 이것 중 하나의 값만 max pooling으로 뽑아낸다. 결과적으로 하나의 window size별로 하나의 값이 나온다.
- 마지막으로 fully connected layer에 집어넣어서 label에 대한 예측을 한다.
2.1 Regularization
- dropout과 weight vector에 대한 L2-정규화 사용하여 정규화해준다.
- dropout
- dropout을 통해 hidden unit의 일부를 확률적으로 버림으로써, hidden unit간에 correlated 되는 걸 막아준다..
- \(z\) = [\(c^1\), . . . , \(cˆ{m}\)]
- m개의 사이즈별 filter를 통해 얻은 max pooled 된 값을 성분으로 하는 벡터
- 즉, 앞선 convolution 연산의 최종 output으로, feed forward network의 입력 vector
-
\[y = w \cdot (z \odot r) + b\]
- \(\odot\)은 element-wise 곱셈을 의미한다.
- r의 성분은 Bernouli(p)를 따른다.
- 즉, p의 확률만큼 z의 성분을 가려서(mask) back propagation 과정에서 update 하지 않는다.
- test 할 때에는, \(\hat{w} = pw\)를 이용한다.
- 앞서 학습 과정에서 p의 확률로 update를 안 했기 때문에 가려지지 않은 weight에 상대적으로 큰 값이 학습되었을 것이므로 p를 이용하여 scaling 해주는 것.
- L2-Normalization
- 매 gradient descent step마다 \(\left\| \textbf{w} \right\|>s\)인 경우, \(\left\| \textbf{w} \right\|=s\)가 되도록 rescale 해준다
3. Datasets and Experimental Setup
대부분 해당 논문이 성능이 좋다는 내용이므로, 포인트만 적었습니다.
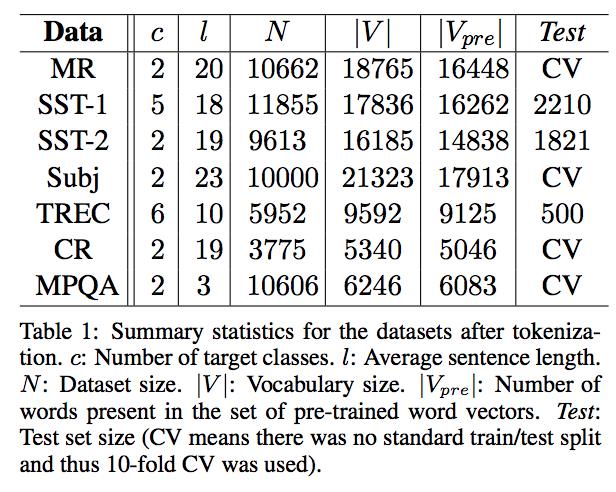
3.2 Pre-trained Word Vector
- 이미 공개된 word2vec을 활용했다.
- 구글 뉴스를 통해 학습된 word2vec
3.3 Model Variations
- CNN-rand
- 모든 단어가 random으로 세팅되며, 학습과정에서 수정된다.
- CNN-static
- 모든 단어를 미리 학습된 word2vec 이용한다. 학습 과정에서 word vector는 수정되지 않는다.
- 기존 corpus에 없는 단어는 임의의 vector를 부여한다.
- CNN-non-static
- 미리 학습된 word2vec 이용하지만, 학습과정에서 fine-tuning 된다.
- CNN-multichannel
- static과 non-static을 함께 이용한다. 즉, CNN의 channel 개념을 적용한다.
- back propagation은 두 개의 채널 중에서 non-static channel만 학습된다.
4. Results and Discussion
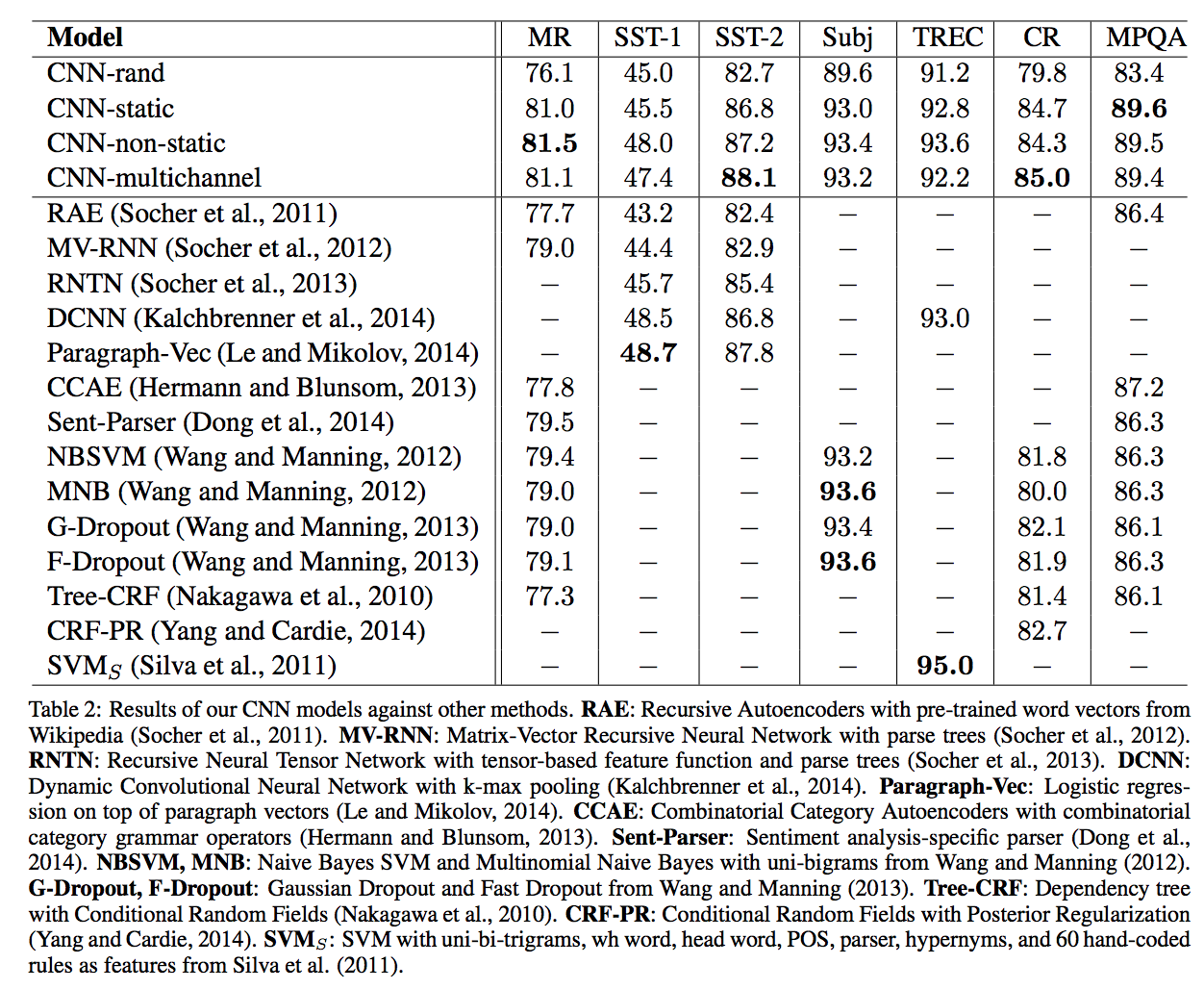
- random initialize model은 성능이 좋지 않았다.
- 기본 static model도 성능이 꽤나 좋아서, word2vec이 단어의 semantic한 특성을 잘 담고 있다고 생각된다.
- 학습과정에서 fine tuning을 하는 것이 역시 대부분의 경우에 가장 성능이 좋았다.
4.1 Multichannel vs. Single Channel Models
- multichannel이 overfitting 방지하면서 데이터 셋에 적절히 fitting 될 것이라고 생각하였다.
- 생각과는 달랐으며, single channel로 non static 모델 쓰는게 더 괜찮은 경우도 많았다.
4.2 Static vs. Non-static Representations
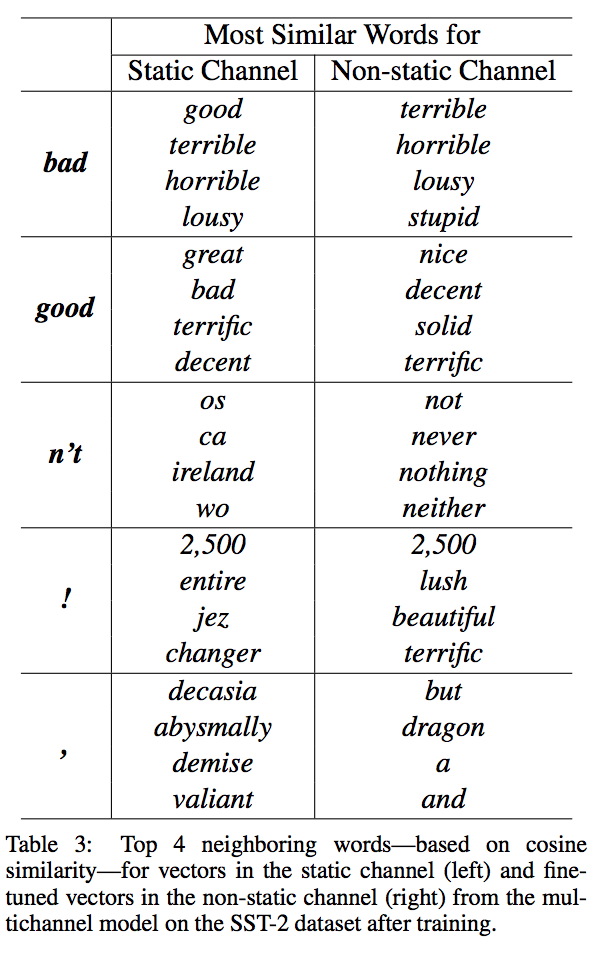
- non-static을 쓰는 것이 주어진 task에 좀더 적절하게 word vector를 바꿔주었다.
- word2vec 모델 자체가 문맥적인 것을 학습하기 때문에 의미가 반대여도 가까운 공간에 존재할 수 있다.
- 이러한 부분이 non-static 모델에서는 수정된다.
- 또한, 기존에 학습된 word2vec에는 없던 token들도 의미적인 특성을 갖도록 학습된다.