0. 들어가며
- 이 프로젝트는 빅콘테스트 2018 Analysis 분야 챔피언리그에 참가한 내용입니다.
- 이 프로젝트 주제는 블레이드 앤 소울 게임 유저 이탈 예측입니다.
- 저희는 블린이 팀으로 참가하여 2등에 해당하는 최우수상(한국정보화진흥원장상)을 수상하였습니다.
- 이 프로젝트는 고동영, 김현우, 김혜주, 손진원과 함께 했습니다.
- 서술의 편의상, 반말로 작성되는 점 양해바랍니다.
1. Intro
빅콘테스트는 매년 여름부터 늦가을까지 진행되는, 우리 나라에서 가장 큰 빅데이터 공모전 중 하나이다. 한국정보화진흥원과 빅데이터 포럼이 공동으로 주최하며, 2018년에는 신한은행, SK telecom, 신한카드, 엔씨소프트가 주관하였다(주관사는 매년 바뀐다). 그 중 우리가 참가한 Analysis 분야 챔피언리그는 엔씨소프트의 주관하에 이루어졌으며, 총 531개 팀이 참가하였다.
Analysis 분야 챔피언리그의 이번 주제는 엔씨소프트의 블레이드 앤 소울 유저 데이터를 이용하여 해당 유저가 얼마만에 이탈할지를 예측하는 것이었다. 우리에게 주어진 데이터는 아래와 같다.
- activity(324MB) : 유저의 인게임 활동 정보 일주일 단위 집계(총 8주)
- payment(3.5MB) : 유저의 주간 결제 정보
- party(2.4G) : 유저간 파티 구성 단위 집계
- guild(4.7MB) : 문파별 문파원 목록 집계
- trade(1.8G) : 유저간 1:1 거래내역 집계
우리 팀원 중 해당 게임을 플레이해본 사람이 없었기 때문에, 도메인 지식을 얻기 위하여 다같이 피시방에 가서 4시간 정도를 플레이해보았다. 또한 기존 유저들의 생각을 얻기 위해 관련 커뮤니티를 조사해보기도 하였다. 후에도 서술하겠지만, 데이터 분석에서 도메인 지식이 정말 중요하다는 것을 다시금 느끼게 되었다. 우리가 사전조사를 통해 얻은 인사이트는 아래와 같다.
- 레이드 등 재밌는 컨텐츠를 즐기기 위해서는 어느 정도 시간투자가 필요하며, 이에 따라 초기유저에 대한 진입장벽 이 존재함을 느낄 수 있었다.
- 기존 유저층 내에서는 다양한 길드와 세력, 파티시스템 등 유저 간의 활발한 상호작용 이 일어났다.
- 아이템 획득을 위한 과금 문제 와 직업간 밸런스 의 문제가 지속적으로 지적되는 것을 확인할 수 있었다.
2. About Data
우리의 데이터는 크게 세 가지의 특징을 갖고 있었다.
2-1. multiclass

우리는 유저를 위의 네 개의 label 중 하나로 분류하는 문제를 풀어야했다. 각 label은 데이터의 측정기간인 8주가 종료된 시점부터 유저의 이탈까지 걸린 기간이며, retained label은 잔류 유저라는 것을 의미한다. training set에서는 각 label 별로 동일하게 1만명의 유저가 배분되어 있었다. 이처럼 label이 2개를 초과하는 경우를 multi-class라 부르며, 이는 (당연히)binary class 분류보다 훨씬 어렵다. 또한, 우리의 최종 모델 평가 기준이 f1-score였기 때문에 더더욱 어려웠다.
2-2. time dependent data
| week | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| playtime | 50 | 40 | 60 | Null | 20 | 70 | 100 | 80 |
위의 데이터는 유저의 게임 플레이 시간에 대한 가상의 데이터이다. 우리 데이터는 위와 같이 유저가 측정기간인 8주 중 게임을 플레이한 주차에 대해서, 그 플레이 시간(및 activity 데이터)이 얼마인지를 보여주었다. 따라서, 각 유저별로 최대 8번의 반복 측정 데이터를 가지고 있었고, 역으로 극단적인 경우에는 마지막 한 주에만 데이터가 있는 경우도 있었다. 이처럼 관찰치가 시간에 종속되어 있다는 특성을 데이터 분석 과정에서 항상 반영해주어야 했다.
2-3. 최초 접속 주차의 특징
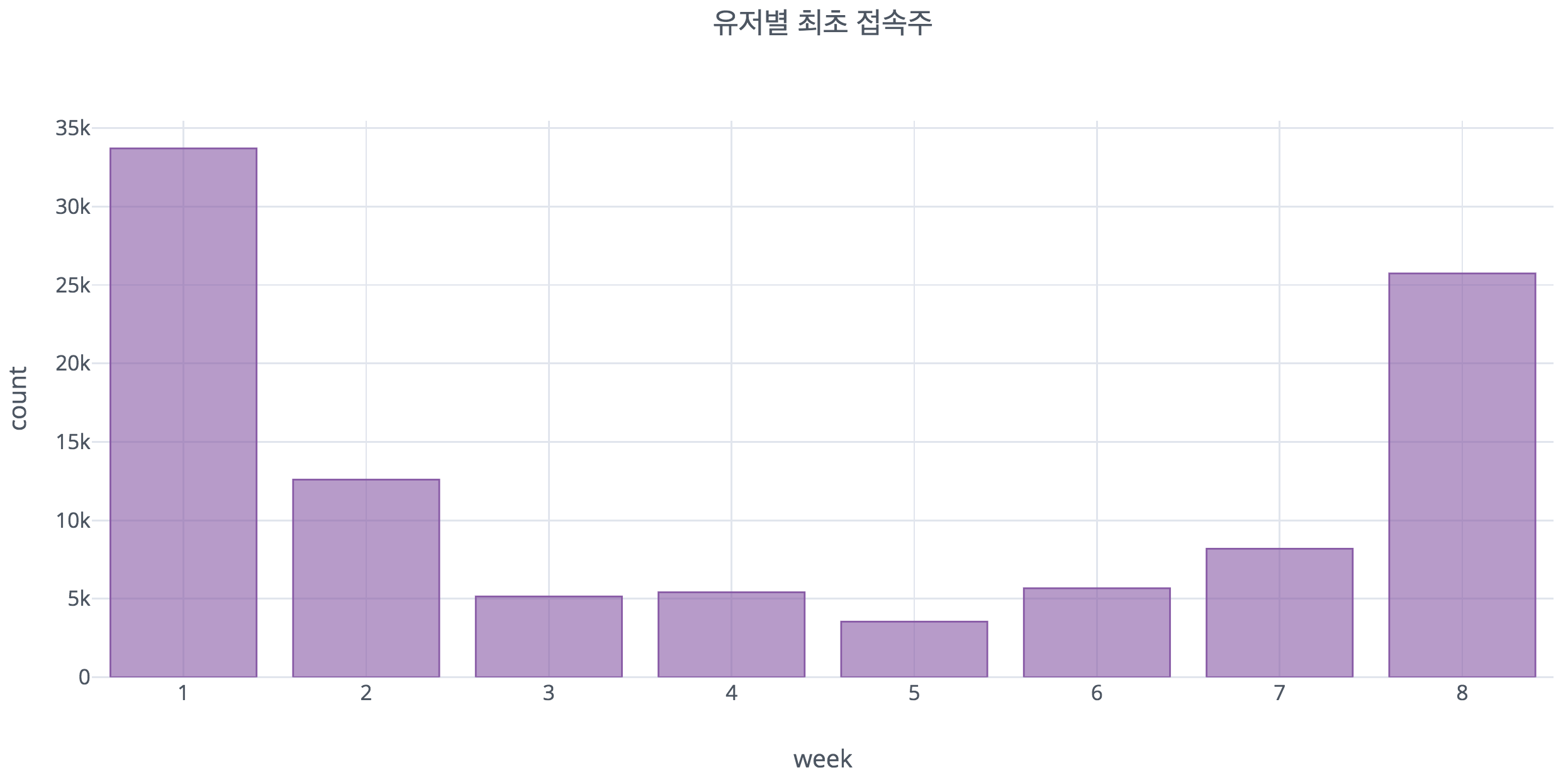
데이터를 분석하는 과정에서 유저별로 측정기간 중 최초로 접속한 것이 언제인지를 분석해보았는데, 위 그림과 같이 1주 또는 8주에 최초로 접속한 유저들이 가장 많은 것으로 나타났다. 이는 우리의 데이터가 가진 특성 때문인데, 이를 다음 파트인 EDA에서 자세히 분석해보았다.
3. EDA
EDA는 너무 양이 많기 때문에 최대한 생략하고 중요한 내용만 서술합니다.
3-1. 데이터 수집 방식으로 인해 발생하는 문제
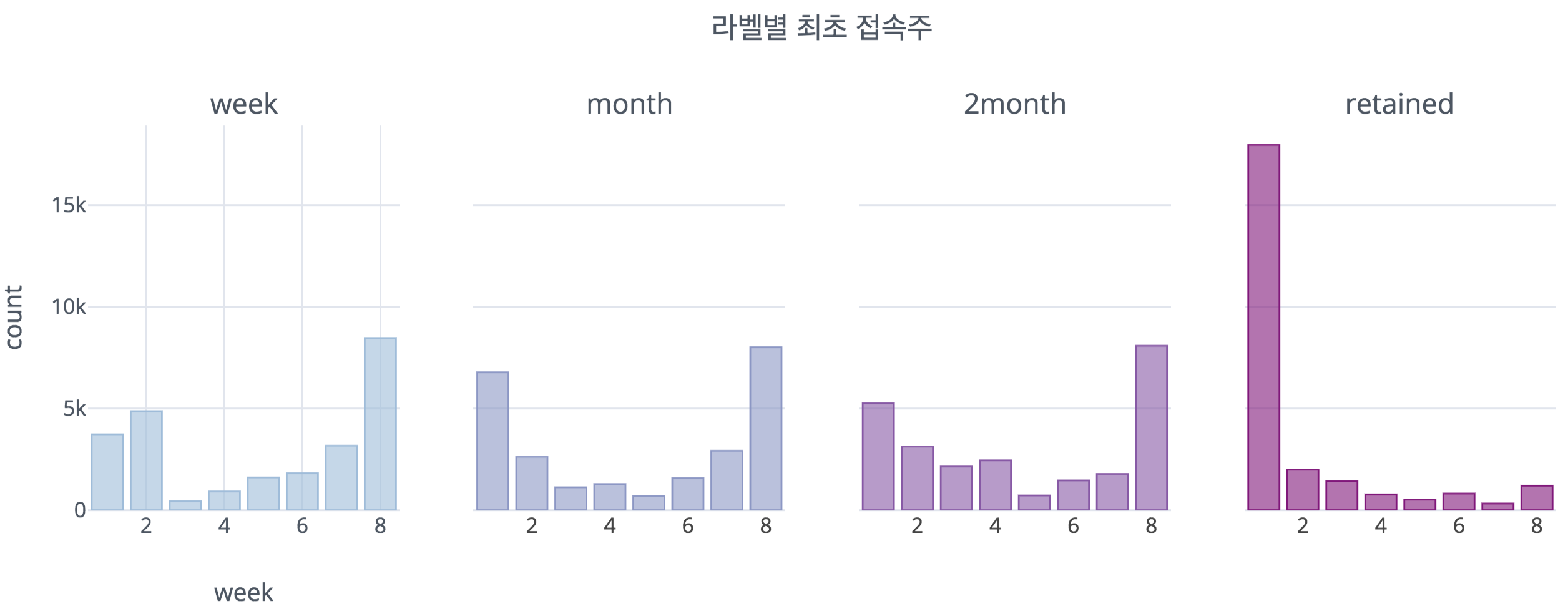
먼저 위에서 보인 유저별 최초 접속주차를 각 class별로 나눠서 그려보았다. 여기서 확인할 수 있듯이, 이탈하지 않은 유저인 retained 유저와 이탈 유저들 간에 확연한 차이가 드러난다. retained 유저는 1주차에 최초로 접속한 사람의 비율이 매우 높은 반면 이탈 유저들은 1주차와 8주차에 최초접속한 사람들의 비율이 높은 것으로 드러난다. 특히 8주차에 최초 접속한 사람이 많은 것으로 나타나는데, 이는 8주의 데이터 측정기간동안 한 주밖에 접속하지 않았다는 것을 의미한다.
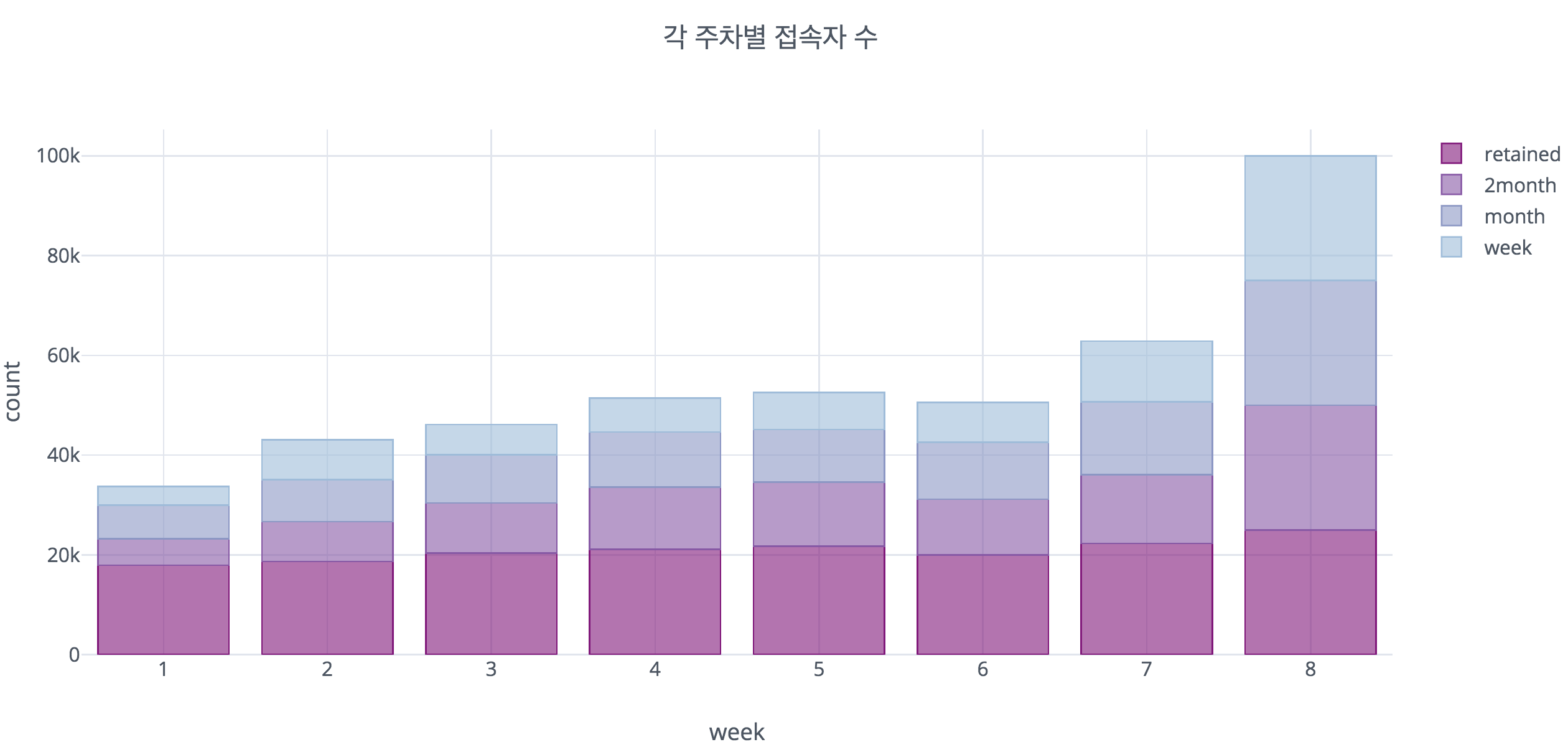
다음은 각 class 별로 해당 주차에 접속했는지 여부를 파악해보았다. 진한 보라색이 retained이며, 색이 옅어지는 순으로 2month, month, week이다. 위에서 확인할 수 있듯 잔류 유저는 8주 내내 꾸준히 접속한 반면, 이탈 유저들은 소수의 꾸준히 접속하는 사람들과 8주에 갑자기 접속한 유저들로 나뉘는 것을 확인할 수 있다. 이는 데이터의 수집방식에서 비롯되는 문제 이다.
해당 데이터는 8주차에 접속한 사람들을 각 class별로 25000명씩 추출하는 방식으로 수집되었다. 따라서 8주에는 모든 class별로 25000명이 접속을 해야만 한다. 하지만 현실적으로 잔류유저는 꾸준히 게임에 접속하던 사람들이었을 가능성이 높은 반면, 이탈 유저는 그렇지 않을 가능성이 높기 때문에 7주에서 8주로 넘어가는 시점에 갑자기 접속비율이 늘어난 것처럼 보이게 된 것이다. 따라서 추후에 데이터 분석을 수행할 때 이러한 데이터 구조상의 특징을 항상 염두에 두고 전처리 하였다.
이렇게 확인한 class별 접속 패턴을 보았을 때, 잔류 유저는 꾸준히 게임을 플레이하는 사람들로 이뤄져있으며, 이탈 유저 들은 일부의 꾸준히 접속하는 유저와 긴 주기로 접속하는 유저, 그리고 8주차에 게임을 처음 시작한 유저로 구성되어 있을 것 이라는 인사이트를 얻게 되었다.
3-2. week 이탈 유저의 접속 패턴
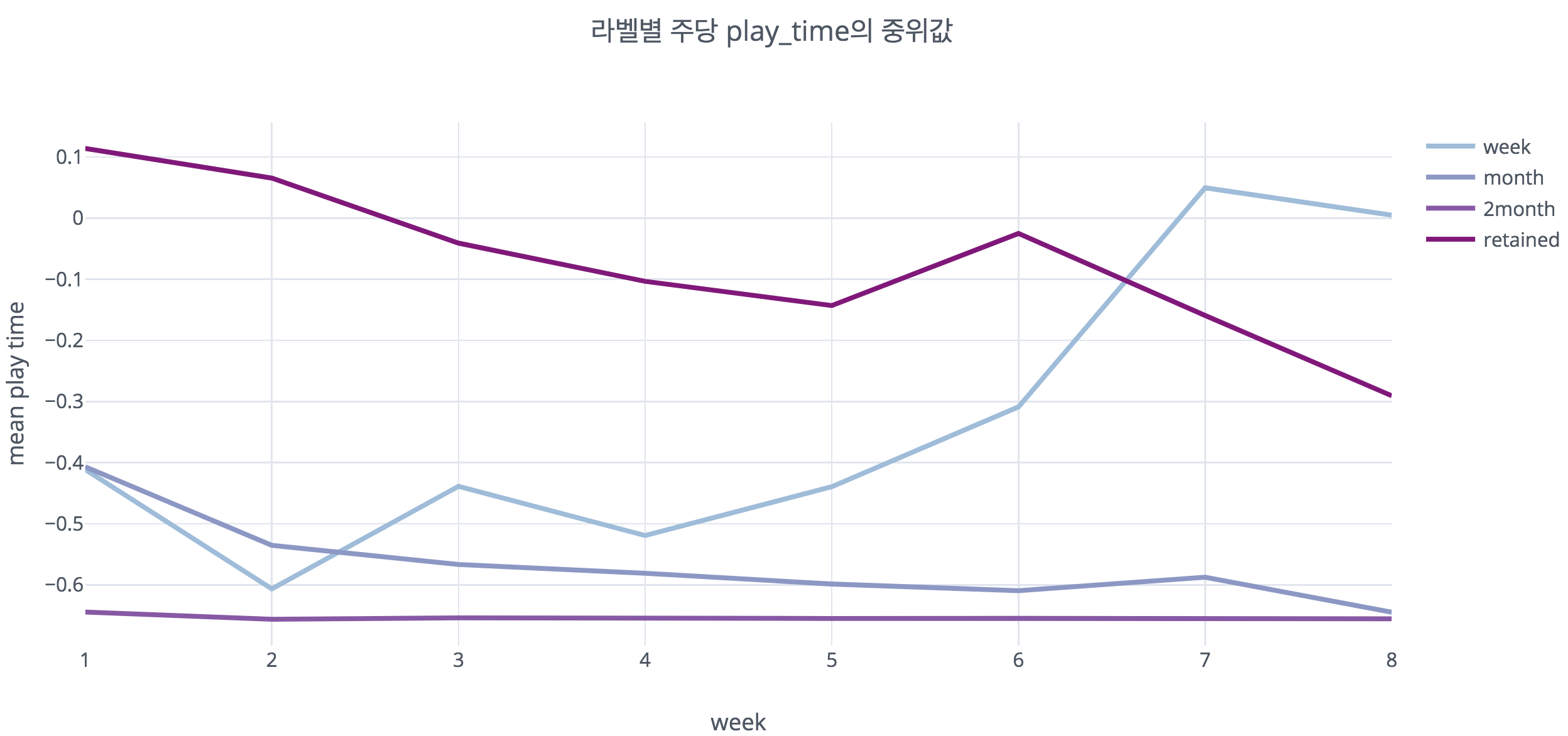
이 그림은 각 class의 각 주차별 게임 플레이 시간의 중위값을 시각화한 것이다. 가장 진한 보라색으로 표시된 잔류 유저들은 예상대로 꾸준히 많은 시간을 매주 플레이하고 있다. 특이하게도, 옅은 파란색으로 표현된 week 이탈 유저들의 주별 플레이 시간이 우상향하는 것을 확인할 수 있다.
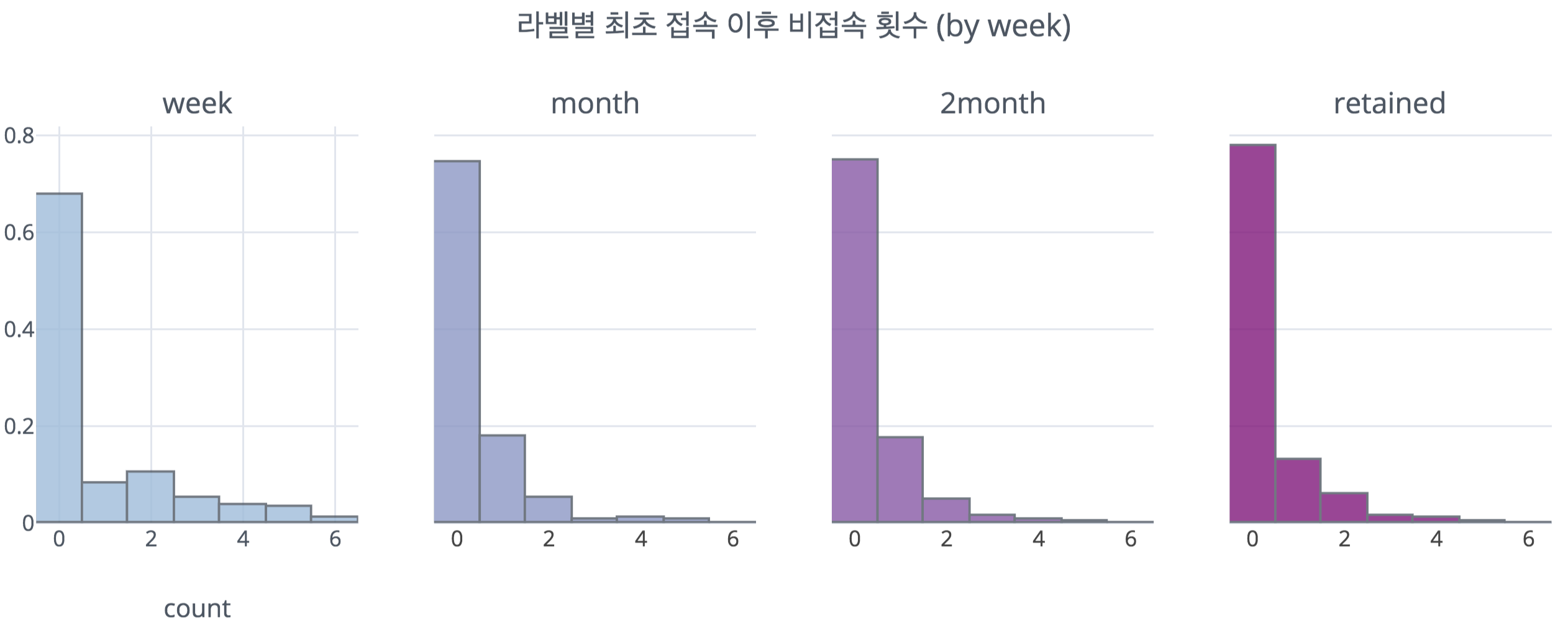
또한 이 그림을 통해 유저가 최초로 접속한 이후 게임을 접속하지 않은 주차를 세어보았을 때, week 이탈 유저는 넓은 범위에 값이 퍼져 있는 반면, 나머지 유저는 비슷한 형태를 띄는 것을 확인할 수 있었다.
위와 같은 일련의 결과는 앞서 확인하였듯이 week유저들의 상당수가 7/8주차에 게임을 처음 플레이하는 초기 유저이거나 긴 주기로 접속하는 유저이기 때문 으로 보인다. 일반적으로 처음 게임을 플레이할 때는 해당 게임을 앞으로 꾸준히 할 것인지 파악해보기 위하여, 상대적으로 긴 시간을 탐색에 쏟게 된다. 또한 긴 주기를 가지고 오랜만에 게임에 접속하는 경우 역시 비슷한 이유로 게임 플레이시간이 길어지게 된다. 이와 달리 month와 2month 유저들은 꾸준히 플레이시간의 중위값이 낮은 것을 확인할 수 있는데, 이는 상대적으로 초기 탐색 또는 긴 주기로 접속하는 유저의 비율이 week에 비해 적기 때문으로 보인다.
3-3. retained(잔류) 유저의 뚜렷한 특징
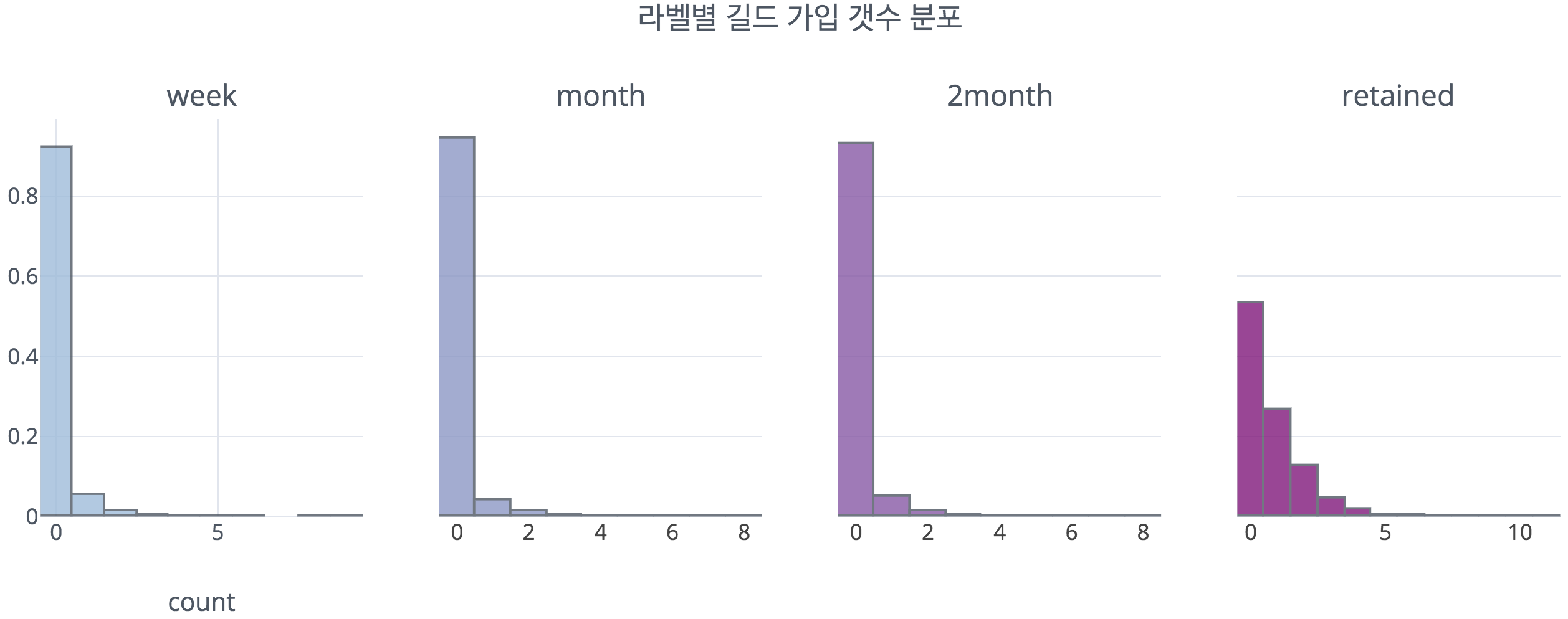
위 그림은 각 class별 길드 가입 갯수를 시각화한 것이다. 우리는 사전 조사를 통해 사회성이 게임 플레이 과정에서 중요한 비중을 차지한다는 것을 알고 있었기 때문에, 이 부분에 특히 집중하여 살펴보았다. 위에서 확인할 수 있듯이, 이탈 유저와 잔류(retained)유저는 길드 가입 갯수의 분포가 뚜렷하게 다른 것으로 보인다. 이는 기존 질적 조사 결과와 일치하며, 이를 통해 도메인 지식이 데이터 분석 과정에서 정말 중요함을 다시금 느낄 수 있었다.
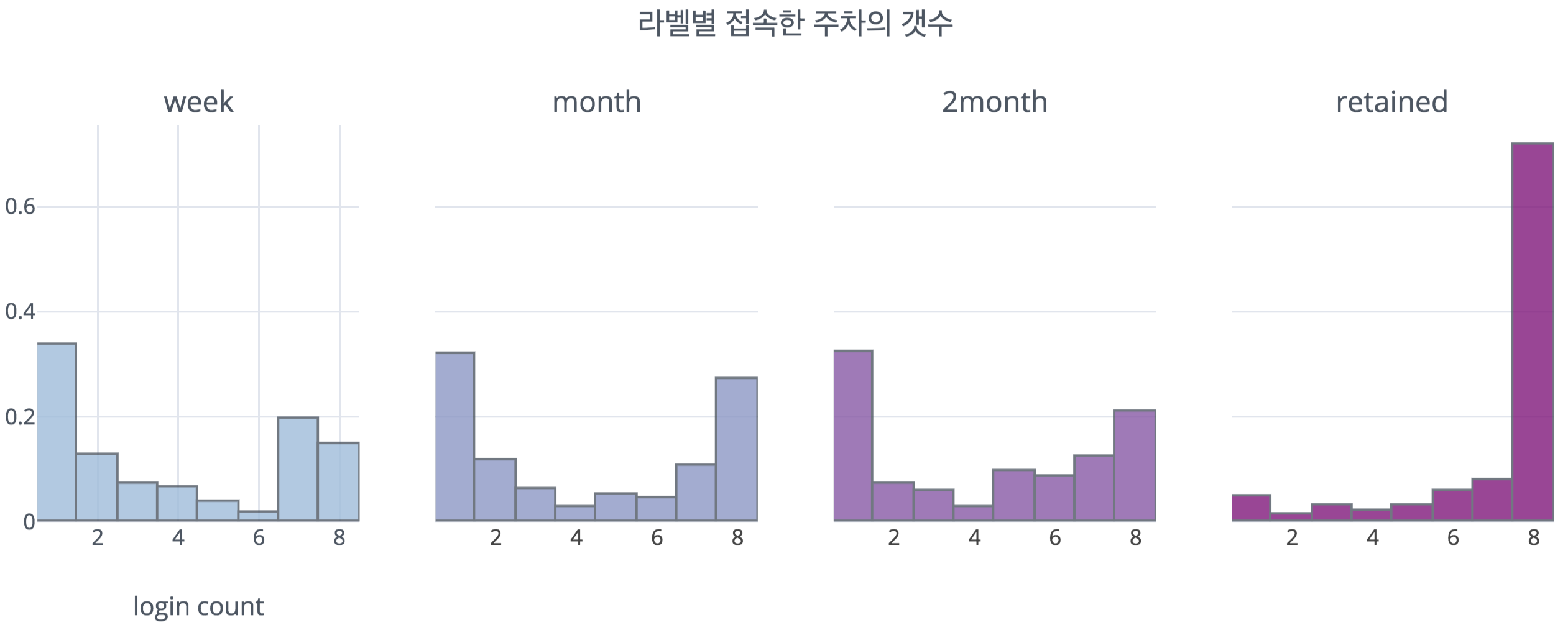
이 그림은 각 class별로 데이터 수집기간인 8주 중 몇 주를 접속하였는지를 세어본 것이다. 잔류 유저들은 데이터 수집기간인 8주 내내 접속을 한 사람들의 비율이 매우 높은 것을 확인할 수 있으며, 이에 따라 잔류 유저는 꾸준히 게임을 하는 기존 유저들이 대다수의 비율이 차지할 것으로 생각되었다. 이와 달리, 이탈 유저들은 꾸준히 게임을 접속한 사람들과 데이터 수집기간 중 게임을 거의 하지 않은 라이트 유저로 크게 나뉘는 것을 확인할 수 있었다.
3-4. EDA 결과
이렇게 변수별 EDA를 모두 수행한 결과, 잔류 유저는 이탈 유저와 다른 패턴 을 보여주는 경우가 많았기 때문에, 분류모형이 쉽게 분류할 수 있을 것이라 생각되었다. 또한 이탈 유저 내에서도 week 이탈 유저는 나머지 두 종류의 이탈 유저와 약간씩 다른 패턴 을 보이는 경우가 있었기 때문에, 이것 역시 분류 모형이 잘 학습할 것이라고 생각되었다. 하지만 month와 2month 이탈 유저의 경우, 대부분의 변수에서 뚜렷하게 구분되는 패턴을 보여주지 않았기 때문에 모델이 학습하는 데에 어려움이 있을 것이라고 생각되었다. 이는 이탈 시점이라는 연속적인 값을 임의의 클래스로 분절했기 때문에 발생하는 현상으로 보이며, 이를 잘 분류하도록 모델을 학습시키는 것이 성능 향상의 중요한 포인트가 될 것이라는 사실을 예상할 수 있었다.
4. Feature Engineering
FE 역시 짧게 정리하고 넘어가겠습니다.
발표 당시 Feature Engineering 과정은 주로 어떠한 변수를 생성했는지에 포인트를 두고 설명하였다. Feature Engineering 과정에 사전에 조사한 도메인 지식과 EDA를 통해 알게된 지식들을 반영해주기 위해 노력하였고, 이 부분을 발표에서도 어필하고자 노력하였다. 가장 중점을 두고 만든 변수는 유저의 사회성에 관한 지표가 될 수 있는 변수 들이었으며, 길드 활동 정도, 파티 활동 정도, 유저별 친구 수, 친구들의 class 비율 등을 추가해주었다. 이러한 사회성 지표들은 추후에 모델링에서도 유의미한 변수로서 활용되었다. 또한 앞서 보았듯이 이탈 class별로 접속 패턴이 다른 형태를 띄었기 때문에, 유저의 접속 패턴을 보여줄 수 있는 변수 들을 추가해주었다.
5. 초기 모델링
초기에 접근한 모델링 방식으로, 크게 딥러닝적 접근과 머신러닝적 접근을 활용하였다. 이 두 모델은 모두 성능상의 문제로 최종 모델로 활용되지 않았으나, 최종 모델에 활용되는 인사이트를 던져주었다.
5-1. 딥러닝적 접근
딥러닝적 접근에서는 NLP 문장분류에서 가장 유명한 딥러닝 모델인 CNN for Sentence Classification을 이 데이터에 적용해보았다. NLP 방법을 쓴 이유는 우리의 데이터 백터가 8주 동안 연속적으로 쌓이는 방식이 일정 길이의 문장을 구성하는 단어에 대한 word vector가 쌓이는 방식과 유사하다고 생각되었기 때문이다. 그 구조는 아래와 같다.
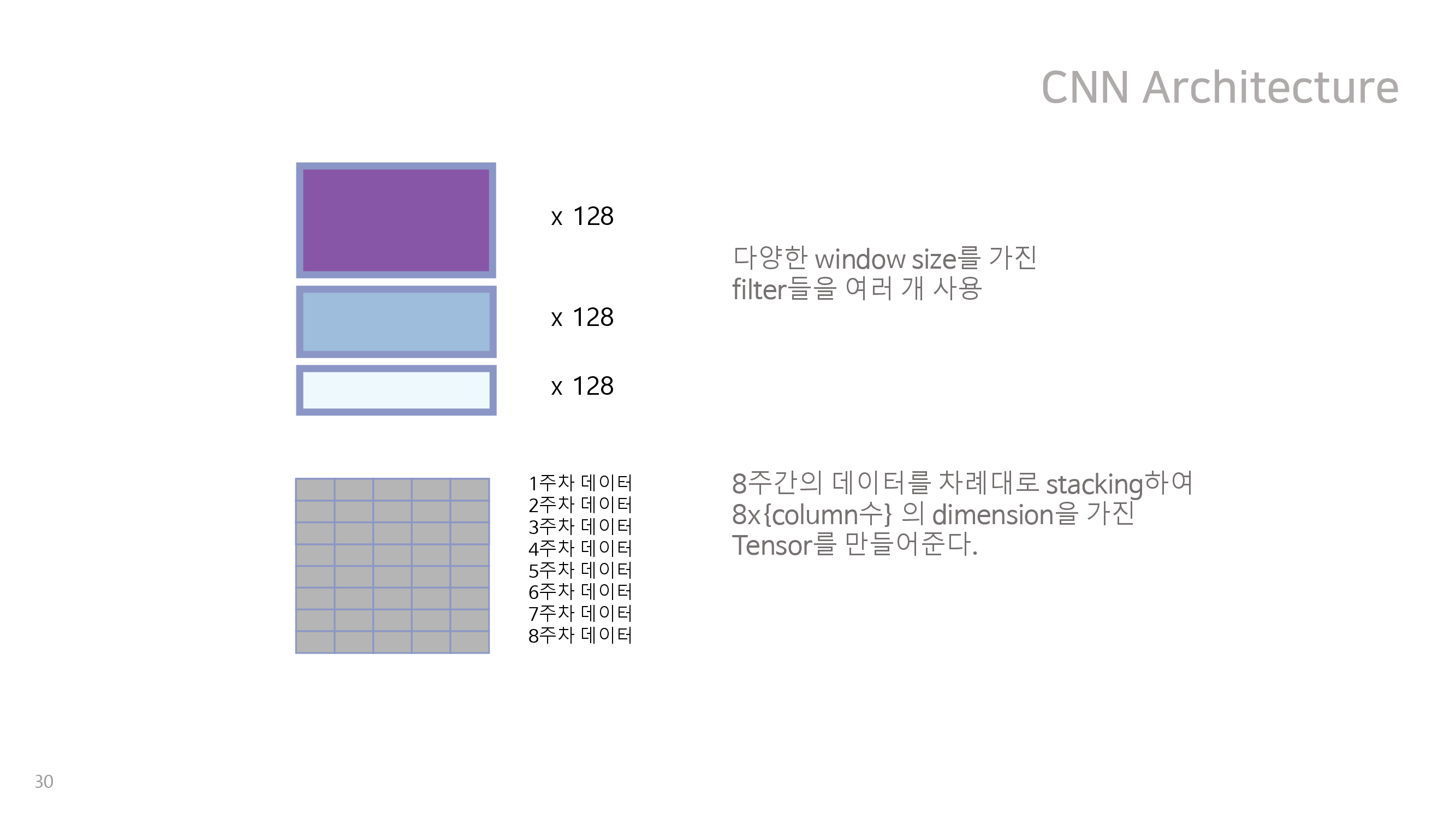
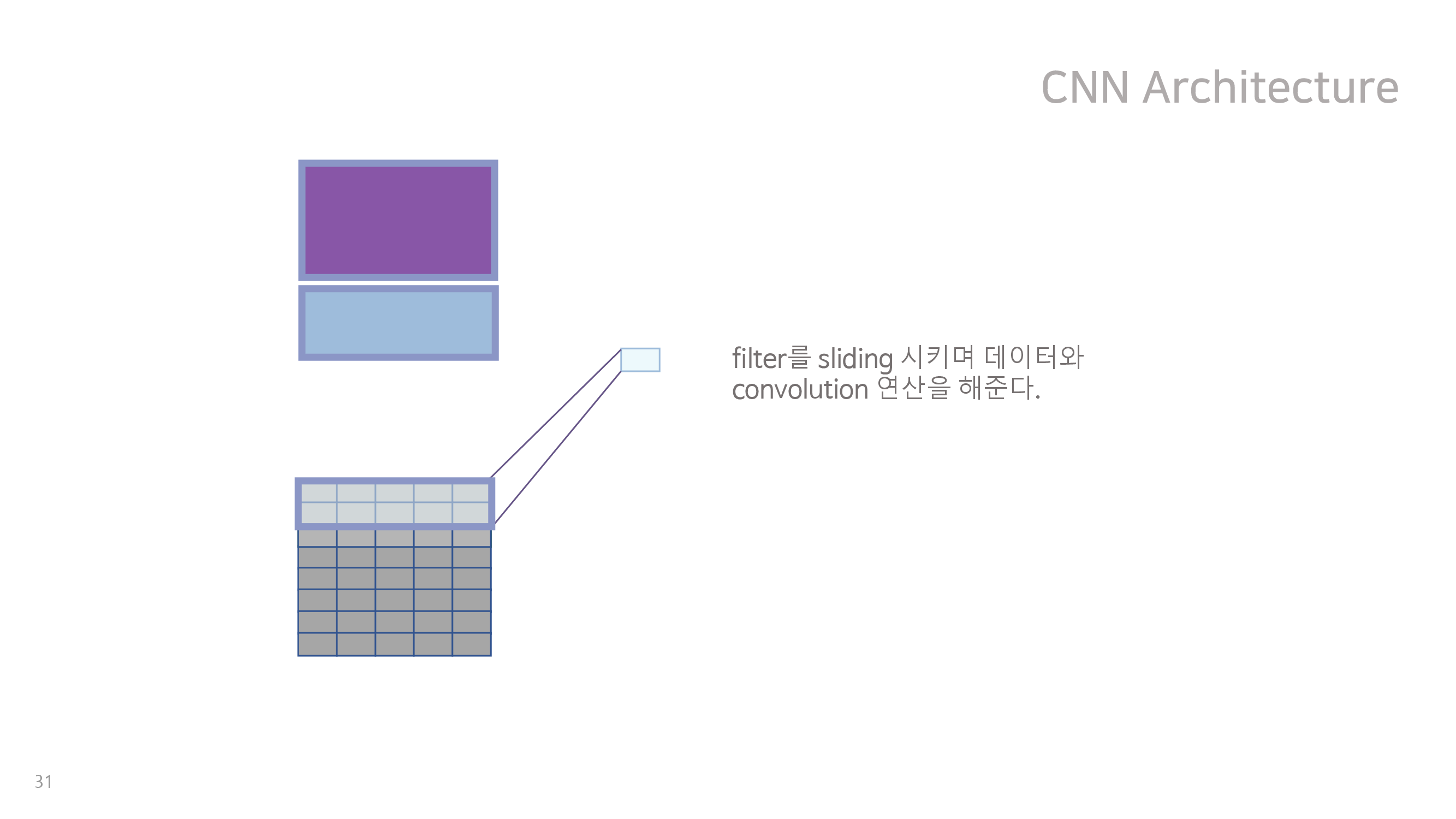

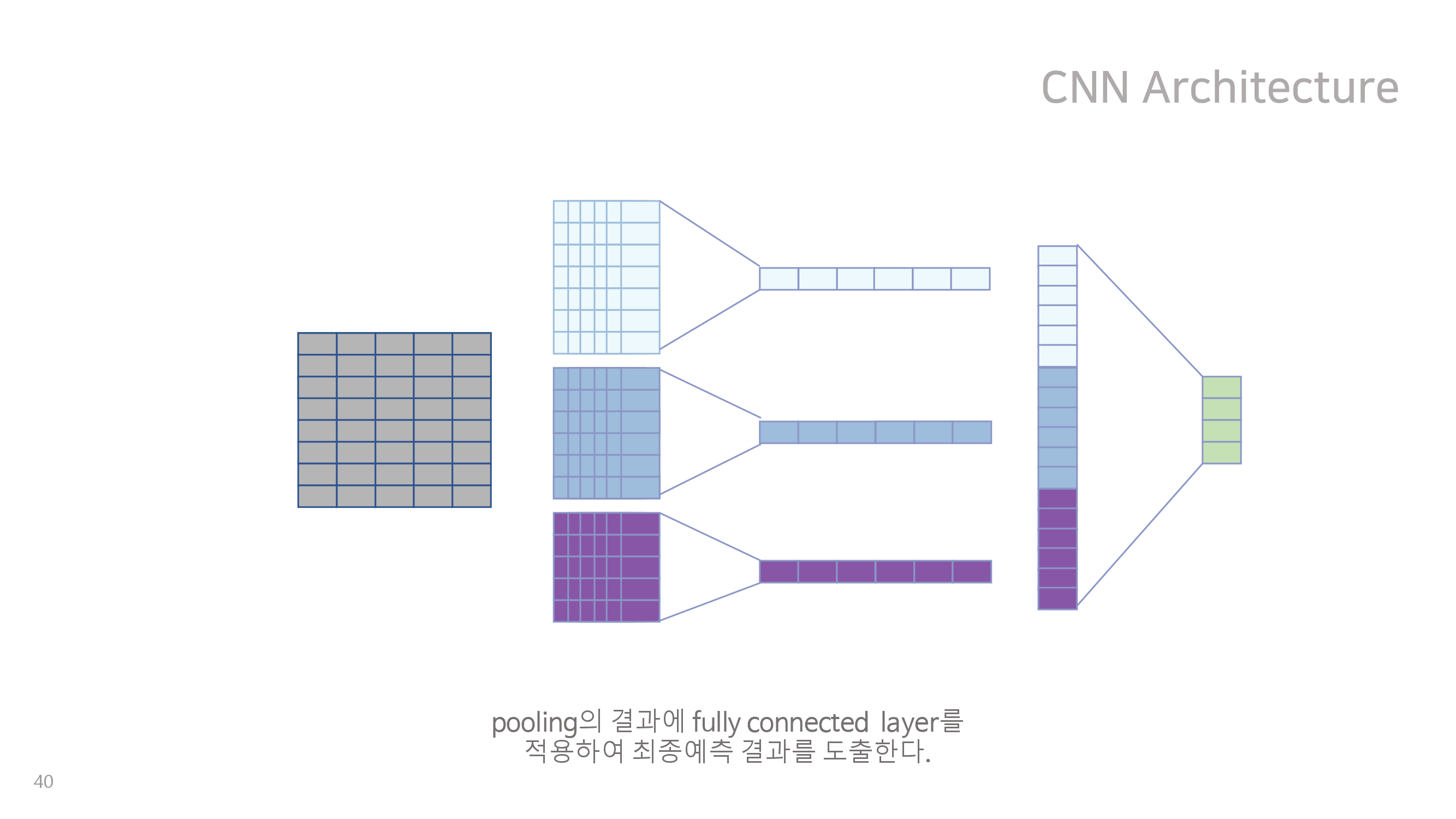
이처럼 다양한 크기를 갖는 kernel을 결합하면 여러 주차 간의 관계가 고려된 분류 모형을 만들 수 있을 것이라 생각되었으나, validation set에 대하여 f1 score가 높지 않았기에 최종적으로 채택되지는 않았다. 이는 우리의 데이터가 가진 변수가 매우 다양하지만, 상당수의 유저가 일부 변수에 해당하는 행동을 측정 기간동안 아예 하지 않아서 의미상 0을 나타내는 값을 가지는 경우가 많았기 때문으로 보인다. 또한 유저가 아예 접속하지 않은 주에 대해서도 의미상 0을 나타내는 값으로 padding 해주었는데, 결과적으로 들어온 데이터 중 상대적으로 의미있는 부분이 적어졌고 신경망이 이를 쉽게 찾지 못했기 때문으로 보인다. 하지만 대회 제출이 종료된 이후에 구조를 변경하여 추가적으로 모델을 돌려보았을 때 f1 score가 우리의 최종 모델에 가깝게 좋아지는 것을 확인 할 수 있었다.
5-2. 머신러닝적 접근
앞서 계속 설명하였듯이 우리의 데이터는 각 유저별로 8주동안 반복 측정된 데이터이며, 각 유저별로 접속횟수가 다르기 때문에 데이터의 형태가 상이하다. 이는 기존의 머신러닝 모델이 받아들이는 데이터의 형식과 다르기 때문에, 데이터를 가공하여 기존의 머신러닝 모델을 이용하고자 시도해보았다. 그 과정에서 유저별 각 주차 값의 중위값을 활용하는 모델과, 유저의 각 주차별 데이터를 각각 다른 유저의 데이터로 보고 독립적으로 모델링 한 뒤에 이를 voting 하는 방식의 repeated predict 모델을 개발하였으나, 모두 성능이 좋지 않았다.
5-3. 최종 insight


이를 포함한 일련의 과정에서 결론적으로 유저의 각 주별 데이터를 가로로 붙이는, flattening 을 시행한 데이터가 최종 데이터 형식에 가장 적합하겠다는 결론을 내릴 수 있었다. 이러한 flattening은 각 주별 변수의 관계를 고려하는 데에 적합하지만 time series 데이터의 특성인 time lag이 일부 무시되는 결점을 가지고 있었다. 따라서 우리는 이 문제를 보완 하기 위해 rolling function을 활용하여 lag variable을 추가하였다. 이는 각 변수의 특정 기간 동안의 관련성을 요약하는 정보를 추가해주는 것이다. 이 방식은 flattening 이후에도 데이터의 시계열적인 특성을 반영시켜줄 수 있게 해주었다.
6. 최종 앙상블 모델
세상에 존재하는 모든 모델은 특정 부분에서 약점을 가지고 있다. 따라서 우리는 이러한 모델들의 힘을 합쳐 각자의 약점을 보완하고 성능의 향상을 얻고자 하였다. 이를 위하여 팀원들은 각자 전처리 단계부터 독립적으로 수행하며 서로 다른 데이터로 각자의 모델을 설계하였고, 이 결과를 가중합하여 최종 분류 결과를 뽑아내었다. 이러한 앙상블 모델을 hyper bagging, 속칭 원기옥 모델이라고 명명하였다.
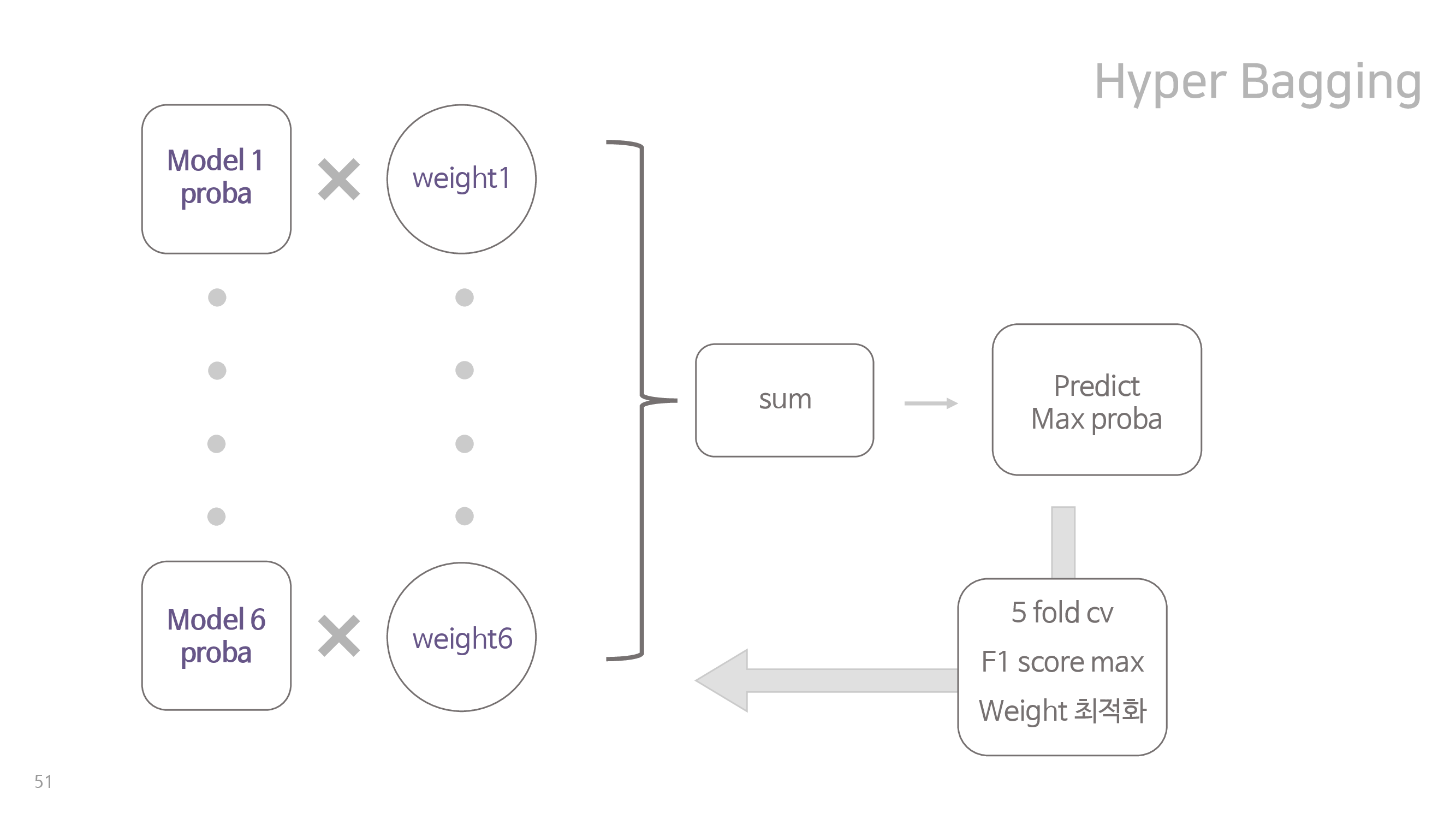
그림을 통해 모델의 구조를 도식화하면 위와 같다. 먼저 팀원들이 각자의 데이터로 서로 다른 모델 여섯개를 설계하고, 이를 이용하여 설계한 모델로 cross validation set의 유저가 4개의 class 각각에 속할 확률을 뽑아낸다. 이를 가중치를 곱하여 합한 뒤, 각 유저별로 가장 속할 확률이 높은 class로 분류한다. 이 과정을 5 fold cross validation 하여 f1 score가 가장 높게 만드는 weight를 학습한다. 이 과정을 통해 최종 모델 여섯개와, 해당 모델에 대한 가중치 여섯개를 학습시킬 수 있다. 이때 대회의 모델 평가기준인 f1 score의 특성상, 네 개의 class 모두를 비슷하게 잘 맞춰야한다는 사실에 집중하였으며, 각 모델의 강점을 합쳤을 때 최적의 f1 score가 나오도록 하는 weight를 찾는 것이 매우 중요했다. 따라서 이러한 목표를 달성하기 위해서 cross validation을 필수적으로 활용하였다.
Hyper bagging에 속하는 여섯 개의 모델은 크게 세 가지 종류의 모델로 구분할 수 있으며, 각각 feature selection을 활용한 모형, 데이터를 접속 주차별로 활용시킨 모형, month/2month를 잘 분류하기 위한 모형이다. 그 설명은 아래와 같다.
6-1. Feature Selected Data를 활용한 모형
flattening을 수행할 경우 유저별로 데이터의 갯수가 8배가 되기 때문에 데이터의 차원이 너무 켜지므로, 머신러닝 모델이 차원의 저주에 빠지고 성능이 저하되는 문제가 발생한다. 따라서 이 모델들은 이를 해결하기 위하여 stepwise selection과 cross validation을 통해 실제 성능 향상에 도움을 주는 변수들만 선택하여 학습하였다. 이 경우, 모델의 성능이 향상되고 학습시간이 줄어드는 장점이 있다. 이렇게 feature 갯수를 줄인 데이터를 활용하여 random forest와 XGBoost를 학습시켰다. 두 경우 모두 hyper parameter를 grid search로 찾아냈으며, RF는 잘 예측하지 못하는 class에 대하여 weight를 추가적으로 주는 방식으로 학습을 도왔다. XGBoost는 잘 찾아내지 못하는 class를 잘 찾아내도록 학습이 되기 때문에 따로 weight를 주지 않았다.
6-2. 최초 접속 주차별로 분리하여 학습시킨 모델
데이터를 단순 flattening 시키는 경우 각 유저가 최초로 접속하기 이전의 데이터도 학습에 사용될 수 있다. 이 경우에 유저의 최초 접속 일자가 해당 게임에 최초로 가입한 날이라면, 자신이 게임에 가입하기도 이전의 데이터가 이탈 예측에 사용되는 문제가 발생하는 것이다. 따라서 유저를 최초 접속 주차를 기준으로 여덟 종류로 나눈 뒤, 각 분류에 해당하는 유저별로 총 8개의 모델을 fitting하여 분류를 하는 모형들이다. 구조는 아래와 같다.
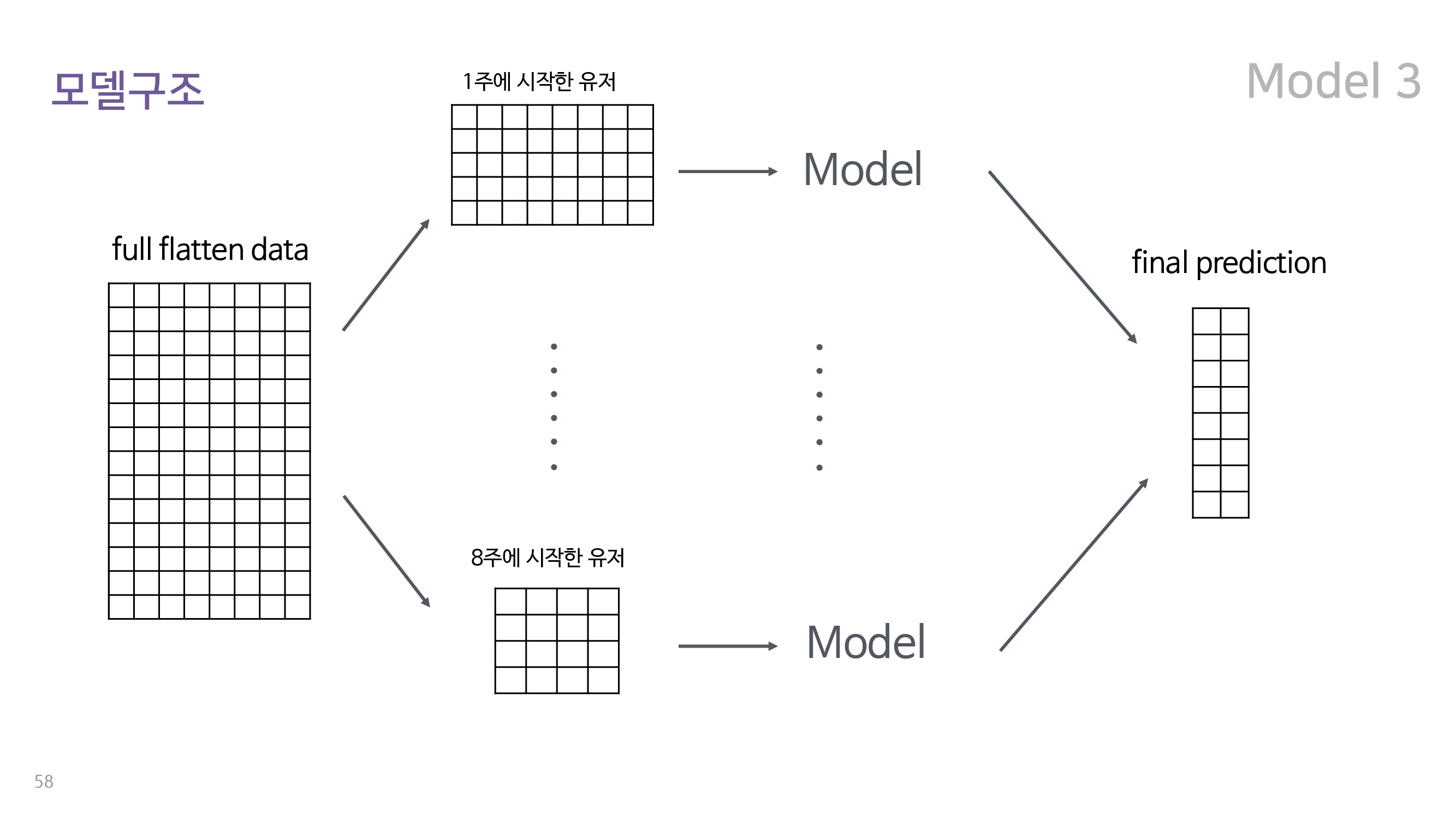
위에서 볼 수 있듯이 전체에 대해서 flattening된 데이터는 유저가 접속하지 않은 주의 경우, 해당 주의 min 값을 padding한 상태이다. 이를 최초 접속 주를 기준으로 8종류의 데이터로 분할한 뒤 각각에 총 여덟 개의 모델을 fitting하고, 이를 통해 유저별 class를 예측하였다. 여기에서도 마찬가지로 random forest와 XGBoost를 사용하였으며, grid search로 hyper parameter 최적화를 수행해주었다.
6-3. month와 2month를 잘 분류하기 위한 모델
앞서 EDA에서도 살펴보았듯이, month와 2month 이탈 유저는 그 특성이 매우 비슷하며 의미적으로 매우 유사하기 때문에 분류가 쉽지 않다. 지금까지 소개한 네 개의 모델 역시 이를 해결하고자 노력하였으나, 그것이 주된 목표는 아니었으며, 2month와 month를 구분하는 것에 어려움이 있음을 확인하였다. 따라서 month와 2month를 구분하는 뚜렷한 목표를 가진 모델들을 설계하여 최종 앙상블 모델이 4개의 클래스의 두드러진 특성을 동시에 학습하는 데에 도움을 주고자 하였다.
이에 따라 설계된 다섯 번째 모델은 one vs rest random forest 이다. 구조는 아래와 같다.
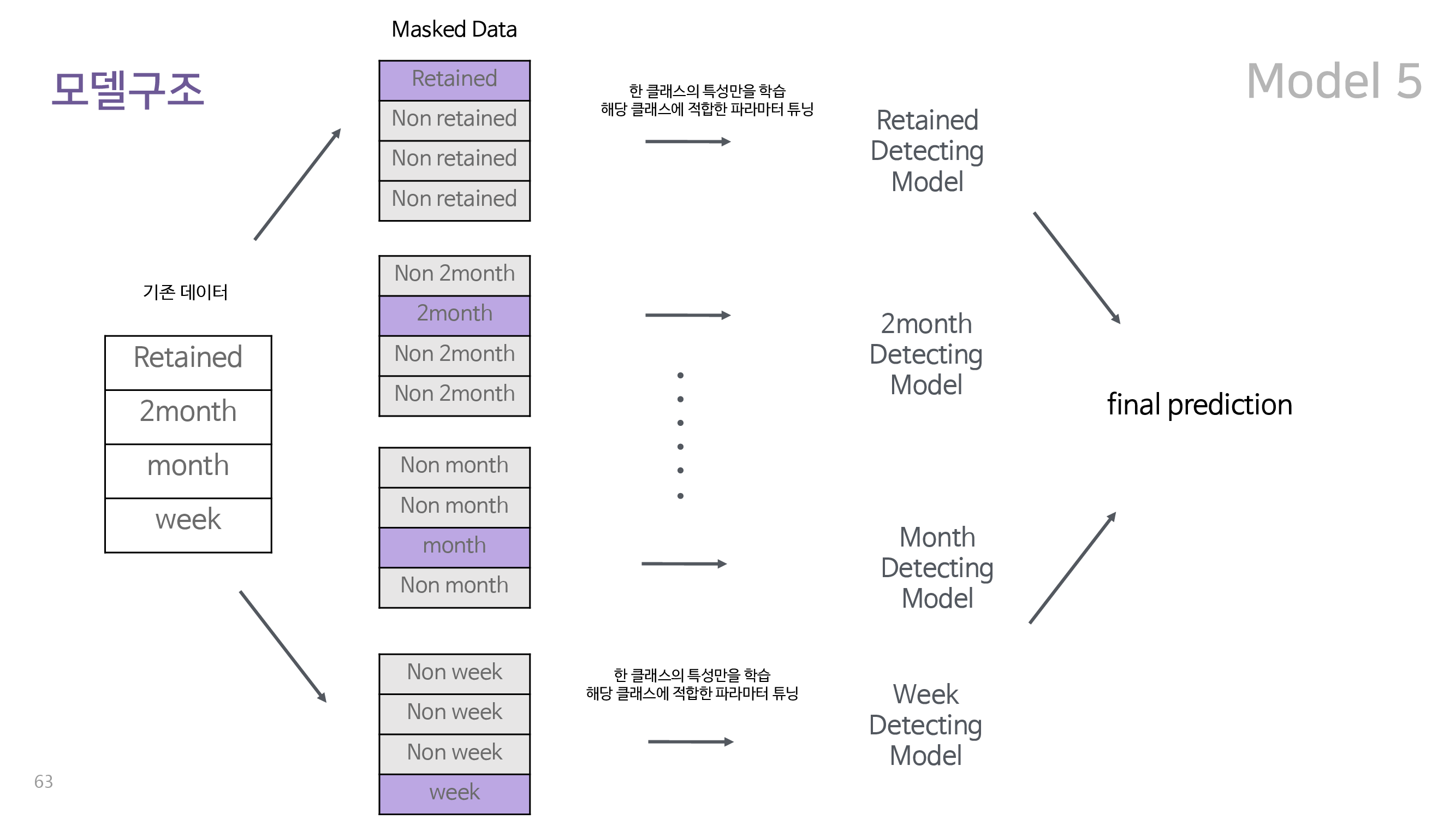
One vs Rest Classifier 는 위 그림에서 볼 수 있듯이 먼저 기존의 데이터를 잔류인지 아닌지, 1주만에 이탈인지 아닌지와 같은 방식으로 네 종류로 표시하고 이를 이용하여 각 유저가 해당 class인지 아닌지만을 학습한다. 이렇게 학습된 네 종류의 모델의 결과를 결합하여 유저가 각 class에 속할 확률을 최종적으로 예측한다. one vs rest 분류기는 클래스간의 연관관계에 관계없이 각 클래스만의 특성을 이용하여 분류를 수행한다는 장점이 있다.
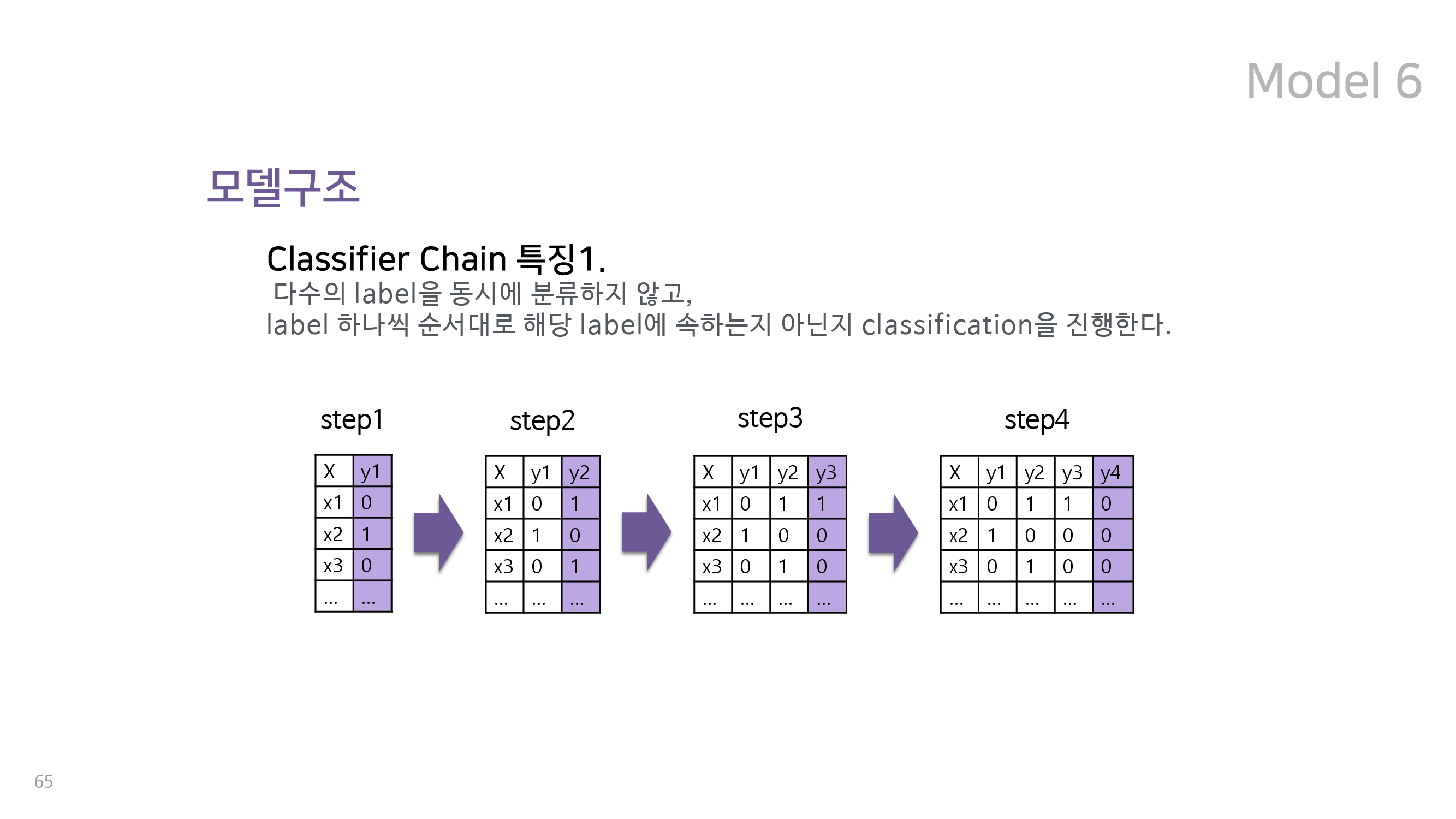
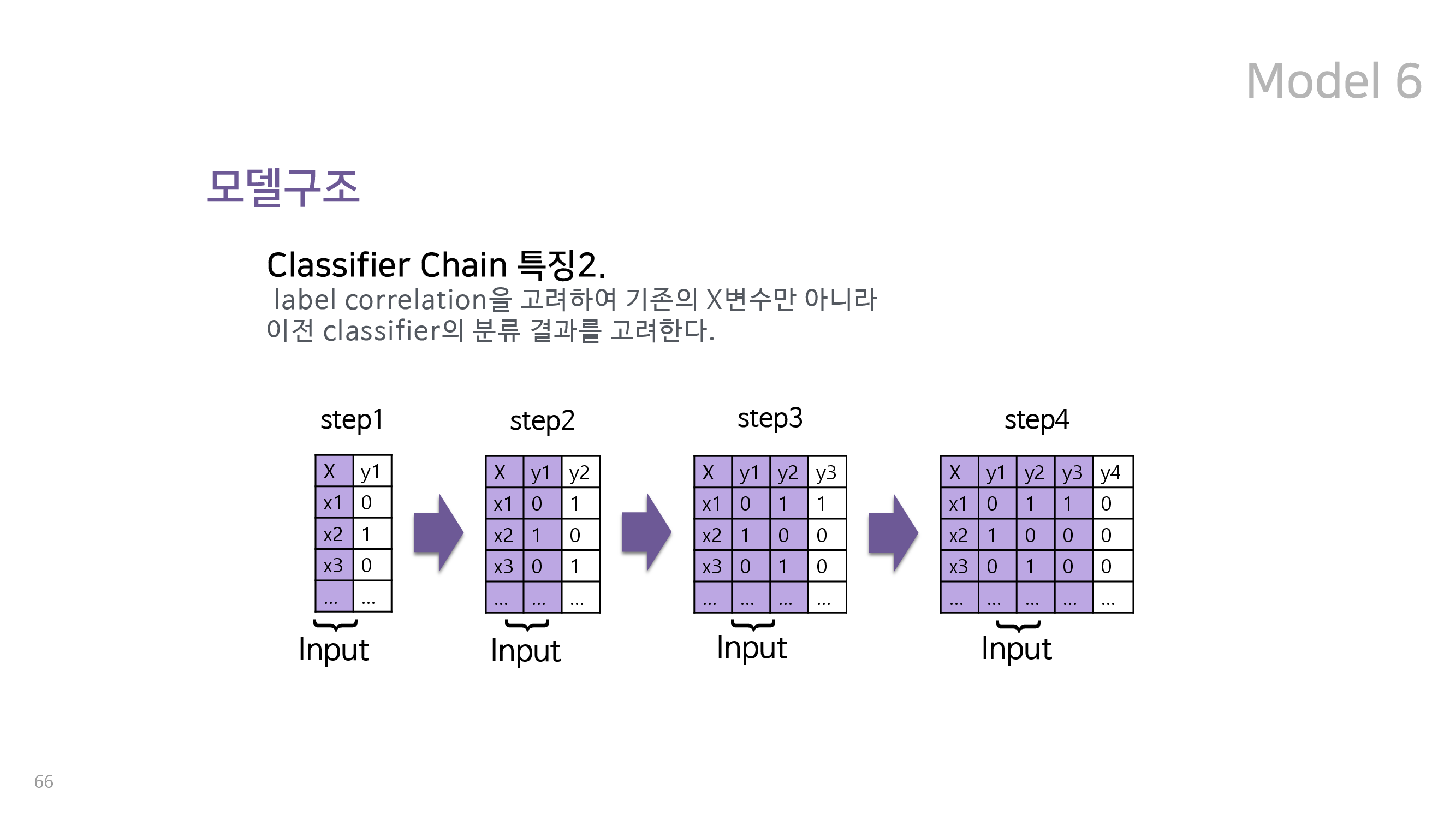
마지막 여섯번째 모델은 multiclass 분류 문제에 많이 사용되는 classifier chain 을 활용한 random forest 이다. 이는 One vs Rest Classifier 와 함께 multiclass 분류 문제에 사용되는 대표적인 방식이다. 이 두 가지 모두 유저가 4개의 class 각각에 속할 확률을 yes/no로 분류한다는 것은 동일하지만, 다섯 번째 모형인 One vs Rest Classifier가 이를 독립적으로 적용하는 대신 classifier chain은 이를 순차적으로 적용한다는 차별점을 가지고 있다. 즉, classifier chain은 특정 유저가 retained인지 아닌지를 예측한 결과를 다시 새로운 변수로 간주하여 week인지 아닌지를 예측하는 데에 사용한다. 전체 구조는 아래와 같다.
6-4. 최종 앙상블 결과
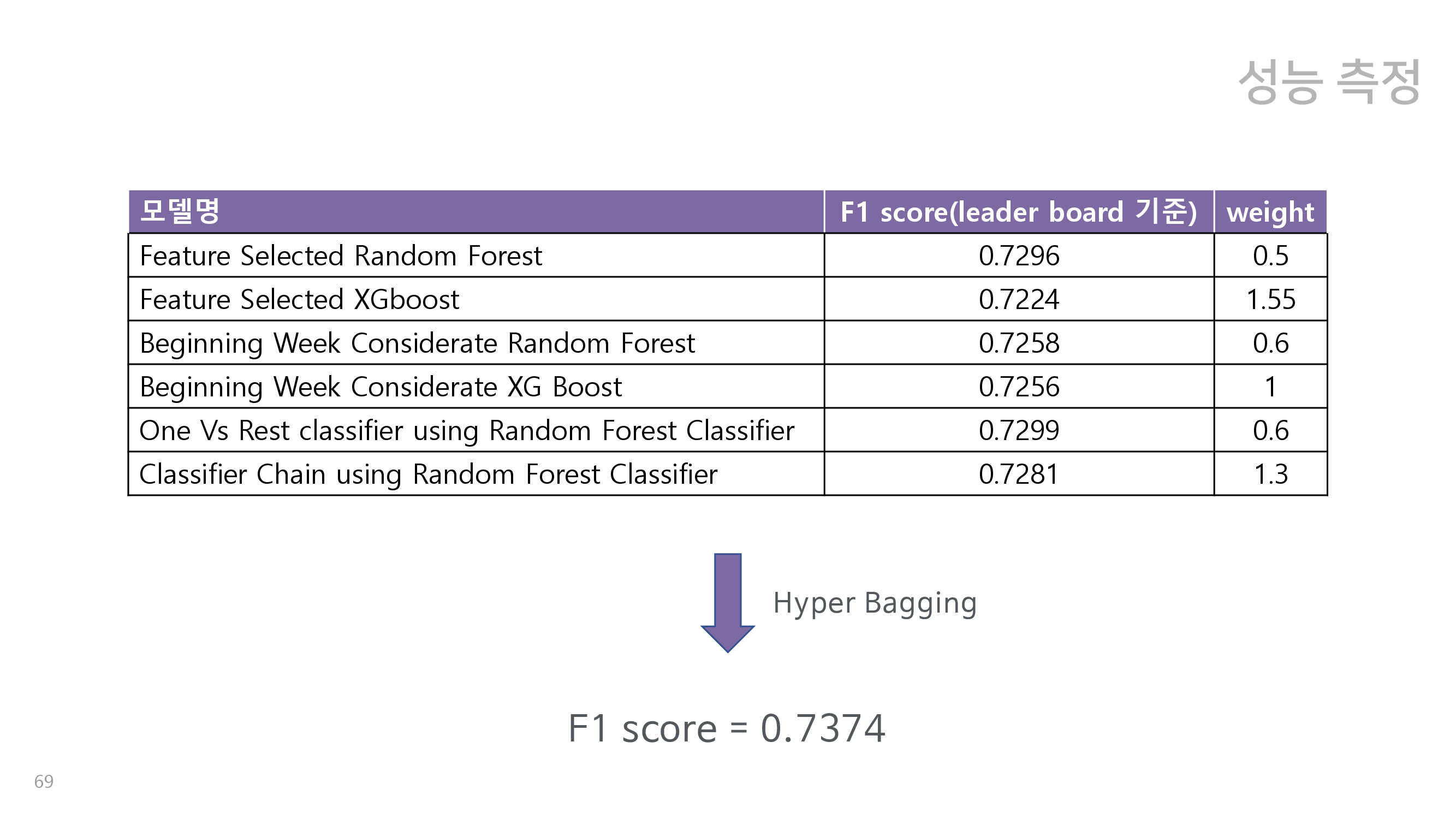
위에서 설명한 세 종류에 해당하는 총 여섯 개의 모델을 앙상블한 결과를 위 그림에서 확인할 수 있다. 각 모델의 성능은 낮았으나, 이를 앙상블한 경우 대회의 평가기준인 f1 score가 크게 향상된 것을 알 수 있다. 이는 앙상블에 속하는 모델 각각에 특별한 목적을 부여하고, 이를 적절하게 가중합한 것의 결과라고 볼 수 있다.
7. 유저 이탈 원인 추정
실제로는 두 종류의 이탈 원인을 찾았으나, 두 번째 이탈 원인은 생략합니다
대회 주최측에서는 유저의 이탈 여부를 찾아내는 문제와 더불어서, 유저의 이탈 원인을 찾아주길 바랬다. 우리는 이를 분류 모형을 이용하여 유저가 이탈할지 잔류할지를 학습한 뒤, 이를 예측하는 데에 유의미하게 이용된 변수를 이용하여 파악해보고자 하였다. 하지만 여기에는 한 가지 문제가 있었는데, 그것은 바로 이상과 현실이 다르다는 것이다. 이상적인 모델은 모델의 성능이 좋아서 결과의 신뢰성이 높고, 독립변수와 종속변수, 즉 이탈 여부와의 관련성을 확인할 수 있는 모델이다. 하지만 현실의 모델은 관련성을 볼 수 있지만 설명력이 낮아서 신뢰성이 낮거나(ex. 선형회귀), 설명력은 높지만 변수간의 관련성을 볼 수 없는 모델(ex. random forest)들만 존재하였다.

우리는 이러한 딜레마를 해결하기 위하여 LIME을 이용 하였다. 대부분의 성능이 좋은 분류 모형은 블랙 박스 모형이기 때문에 그 속을 확인할 수 없는데, LIME은 이를 열어볼 수 있게 해주며 결과적으로 성능이 좋은 모델에서도 변수간의 관련성을 확인할 수 있게 해준다. LIME은 관심이 있는 변수마다 noise를 줬을 때, prediction 값이 얼마나 변하는지를 이용하여 해당 변수의 중요도를 파악하는 방식으로 동작하며, 이를 이용하여 모델이 어떠한 판단을 내린 근거가 무엇인지 파악할 수 있게 도와준다. 따라서 우리는 성능이 좋은 모델이 파악하였을 독립변수와 종속변수 간의 깊은 관계를 열어볼 수 있게 되었다.
우선 유저를 이탈/ 잔류만으로 구분한 뒤, cross validation accuracy를 90% 이상으로 올리도록 모델을 학습시켰다. 이때, 실제 이탈 유저를 이탈할 것이라고 예측하는 데에 주요하게 이용되는 변수들을 모아서, 이들의 순위를 메기고 분석하였다. 아래는 이를 통해 우리가 찾은 관련성이 높은 변수들을 시각화한 결과이다.
7-1. 동료가 있는가
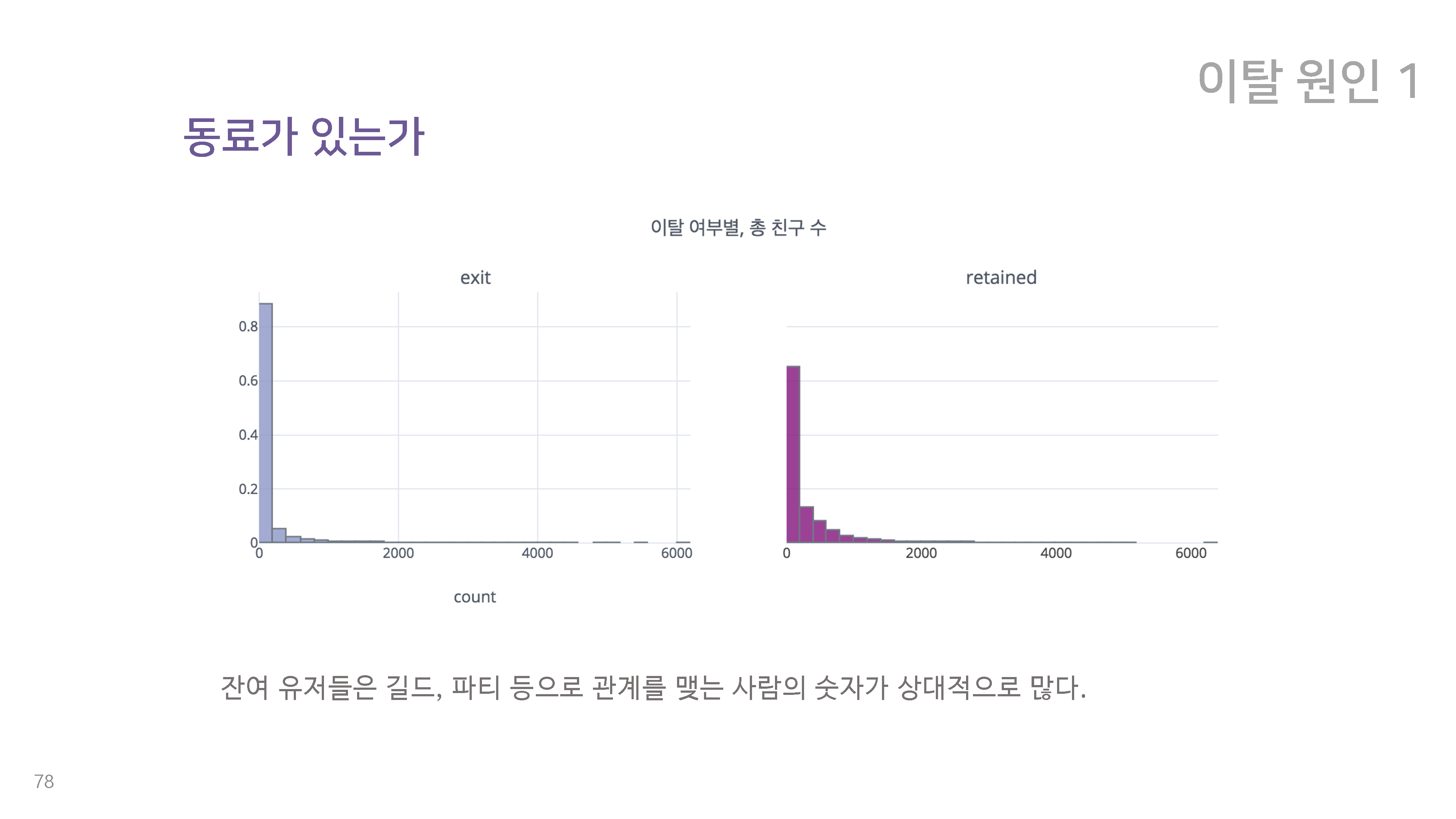
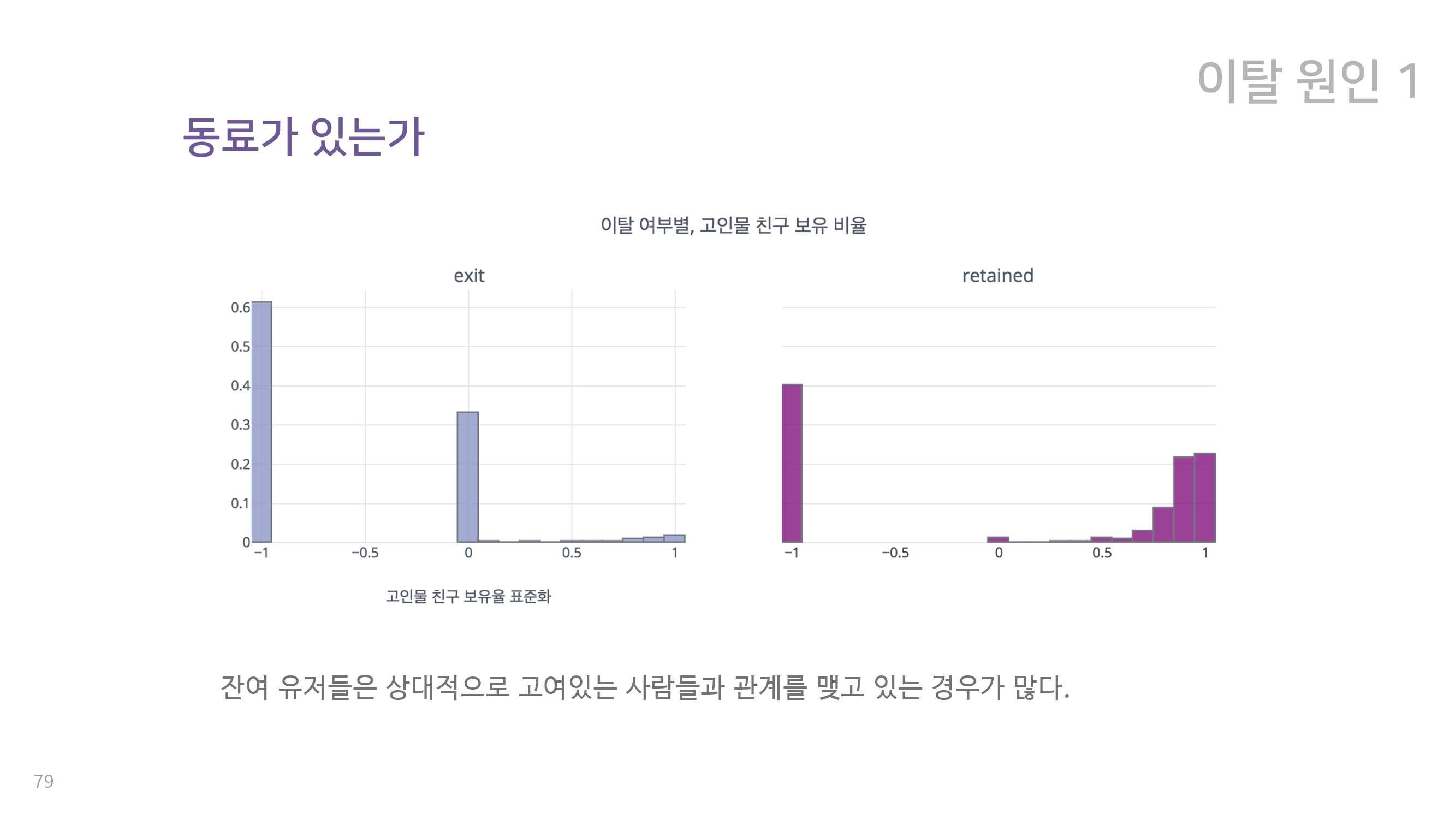
이를 바탕으로 우리가 찾은 첫 번째 이탈 원인은 동료가 있는지 여부 이다. 위에서 확인할 수 있듯이, 이탈 유저는 잔류유저에 비해 길드와 파티 등으로 관계를 맺는 사람의 수가 현저히 적다. 또한 각 유저의 친구 중 열성(많이 접속하는) 유저의 비율이 얼마나 되는가를 측정해 보았을 때도, 이탈 유저와 잔류 유저는 확연한 차이를 보여준다. 잔류 유저는 이처럼 친구 수도 많고, 열성 유저 친구도 많은 것으로 확인이 된다. 이를 바탕으로 우리는 친한 친구의 존재 여부가 이탈에 영향을 준다고 결론내렸다. 특히 린드버그의 말처럼 훌 륭한 의사소통은 자극적이고 중독적이기 때문에, 의사소통의 여부가 유저가 재접속을 하는데에 큰 영향을 미치리라고 보았다.
8. 정리 및 소감
마무리니까 존댓말을 사용합니다
위의 설명을 통해 우리 블린이 팀이 2018 빅콘테스트 Analysis 분야 챔피언리그 블레이드 앤 소울 게임 유저 이탈 예측 모형 을 수행한 과정을 간단히 설명해보았습니다(힘들어서 생략을 많이 했습니다…). 대회가 끝나고 시간이 많이 지난 지금에서야 후기를 쓰게 되었는데, 대회에 참가하는 과정에서 새로운 기술을 스스로 공부하기도 하고, 발표 현장에 가서 우리가 알지 못했던 기술들도 알게 되어서 굉장히 재밌었습니다. 그 동안 같이 공부하는 친구들 안에서 한정된 지식의 재생산만 하고 있었던 것은 아닌지 반성하는 계기도 되었습니다. 올해(2019년)도 곧 빅콘테스트가 시작될 텐데, 아직 문제가 공개되지는 않았지만 혹시라도 저희와 비슷한 문제를 풀게되어 이 포스트를 찾게되는 분들이 있는 경우를 대비해 개인적으로 저희 팀이 개선했으면 좋았을 것들을 적어봅니다.
- 모델 성능이 가장 중요한 것은 아니다.
- 저희의 경우, 리더보드를 기준으로 상위 30팀에게만 최종 발표 기회를 주었습니다. 저희는 최종 수상에 이 리더보드 점수, 즉 모델의 성능이 많은 영향을 미칠 것이라고 생각해서 모델 성능을 올리는 것에 굉장히 많은 노력을 하였습니다. 하지만 결과적으로 볼 때, 모델의 성능은 최종 수상에 critical한 영향을 미치는 것 같지는 않습니다. 성능이 좋아도 더 낮은 상을 받기도 하고, 성능이 상대적으로 낮아도 모델 설계에 대한 철학과 이탈 원인 추정이 잘 되면 높은 상을 받았습니다. 따라서 어느 정도의 성능이 나와서 발표 기회를 받게될 것 같다면 더 이상 성능을 올리는 데에 집중하지 말고 추가적인 과제(유저 이탈 원인 추정) 및 발표 준비에 더 집중하는 것이 좋을 것 같습니다.
- bayesian hyperparameter tuning을 활용하자.
- 위에서 모델 성능이 중요하진 않다고 했지만 그건 발표 기회가 주어지는 경우에 해당되고, 일단 30등 안에 들어야 발표 기회가 주어지기 때문에 기본적으로 어느 정도의 성능은 나와줘야 합니다. 저희는 이전까지 bayesian hyperparameter tuning을 잘 알지 못했는데, 대회 발표장에 가서 다른 팀을 통해 해당 방식의 강력함을 확인하고 굉장히 놀랐습니다. 대회 참가팀의 능력치가 매년 올라가는 것은 확정적이기 때문에, 앞으로의 대회에서는 해당 방법이 baseline이 되지 않을까 생각해봅니다.
- 시각화가 중요하다
- 뒤에서 지켜본 결과 발표 현장에서 심사위원 분들은 발표를 듣기도 하지만, ppt를 개인적으로 계속 읽어보는 경우가 더 많았고, 특히 EDA 부분을 많이 살펴보고 계셨습니다. 저희 팀은 EDA 내용면에서는 따로 지적받지는 않았지만, 색상 조합에서 지적을 받았습니다. 발표자료 시각화는 제가 담당하였는데, 저희가 가진 4개의 라벨이 이탈 시점에 대한 것이고, 이것은 분명 순서가 있는 라벨 이기 때문에 각 라벨의 색을 같은 색상 안에서 명도 및 채도만 변화해나가는 방식으로 시각화하는 것을 선택하였습니다. 하지만 심사위원 분께서는 과장을 좀 더해서 무지개 색깔처럼 뚜렷하게 구분되는 방식의 색상 조합을 선호하시는 것 같았습니다. 사실 제가 봐도 장단점이 명확한 색상 선택이라 일종의 도전정신으로 선택하긴 했습니다… 제가 ppt의 대표색으로 고른 색상이 하필 2018년 팬톤 컬러인 울트라 바이올렛이라서 심사위원분의 컴퓨터에서 더 잘 안 보였던 것 같기도 합니다. 따라서 시각화를 하실 때는 미적인 고려보다는 눈에 확 띄는 원색 위주의 색상 조합을 사용하면 더 좋을 것 같습니다.
- 딥러닝은 잘못이 없다. 우리가 잘못했을 뿐…
- 위에서 잠깐 언급했듯이 저희의 딥러닝 모델은 초기 성능은 안 좋았지만 추후에 수정해서 다시 돌려보니 좋은 성능을 보여줬습니다. 2018 빅콘테스트에서는 딥러닝을 중점적으로 쓴 팀이 없었고, 사용한 팀도 앙상블 모델 안에 간단한 인공신경망이 포함된 방식으로 썼던 것으로 기억합니다. 따라서 딥러닝을 제대로 사용해서 좋은 성능을 낸다면 독보적으로 눈에 띄지 않을까 생각해봅니다. 물론 데이터가 딥러닝에 적합한 데이터인 경우에 한합니다.
저는 참가한 팀의 일개 팀원일 뿐이고 자세한 심사 기준을 알지는 못하니 참고 용도로만 보시면 좋을 것 같습니다. 참가하시는 모든 분들에게 좋은 결과가 있기를 바랍니다.